Pull livepatching updates from Jiri Kosina:
- fix for patching modules that contain .altinstructions or
.parainstructions sections, from Jessica Yu
- make TAINT_LIVEPATCH a per-module flag (so that it's immediately
clear which module caused the taint), from Josh Poimboeuf
* 'for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/jikos/livepatching:
livepatch/module: make TAINT_LIVEPATCH module-specific
Documentation: livepatch: add section about arch-specific code
livepatch/x86: apply alternatives and paravirt patches after relocations
livepatch: use arch_klp_init_object_loaded() to finish arch-specific tasks
Pull MD updates from Shaohua Li:
"This update includes:
- new AVX512 instruction based raid6 gen/recovery algorithm
- a couple of md-cluster related bug fixes
- fix a potential deadlock
- set nonrotational bit for raid array with SSD
- set correct max_hw_sectors for raid5/6, which hopefuly can improve
performance a little bit
- other minor fixes"
* tag 'md/4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/shli/md:
md: set rotational bit
raid6/test/test.c: bug fix: Specify aligned(alignment) attributes to the char arrays
raid5: handle register_shrinker failure
raid5: fix to detect failure of register_shrinker
md: fix a potential deadlock
md/bitmap: fix wrong cleanup
raid5: allow arbitrary max_hw_sectors
lib/raid6: Add AVX512 optimized xor_syndrome functions
lib/raid6/test/Makefile: Add avx512 gen_syndrome and recovery functions
lib/raid6: Add AVX512 optimized recovery functions
lib/raid6: Add AVX512 optimized gen_syndrome functions
md-cluster: make resync lock also could be interruptted
md-cluster: introduce dlm_lock_sync_interruptible to fix tasks hang
md-cluster: convert the completion to wait queue
md-cluster: protect md_find_rdev_nr_rcu with rcu lock
md-cluster: clean related infos of cluster
md: changes for MD_STILL_CLOSED flag
md-cluster: remove some unnecessary dlm_unlock_sync
md-cluster: use FORCEUNLOCK in lockres_free
md-cluster: call md_kick_rdev_from_array once ack failed
When a CPU is physically added to a system then the MADT table is not
updated.
If subsequently a kdump kernel is started on that physically added CPU then
the ACPI enumeration fails to provide the information for this CPU which is
now the boot CPU of the kdump kernel.
As a consequence, generic_processor_info() is not invoked for that CPU so
the number of enumerated processors is 0 and none of the initializations,
including the logical package id management, are performed.
We have code which relies on the correctness of the logical package map and
other information which is initialized via generic_processor_info().
Executing such code will result in undefined behaviour or kernel crashes.
This problem applies only to the kdump kernel because a normal kexec will
switch to the original boot CPU, which is enumerated in MADT, before
jumping into the kexec kernel.
The boot code already has a check for num_processors equal 0 in
prefill_possible_map(). We can use that check as an indicator that the
enumeration of the boot CPU did not happen and invoke generic_processor_info()
for it. That initializes the relevant data for the boot CPU and therefore
prevents subsequent failure.
[ tglx: Refined the code and rewrote the changelog ]
Signed-off-by: Prarit Bhargava <prarit@redhat.com>
Fixes: 1f12e32f4c ("x86/topology: Create logical package id")
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Len Brown <len.brown@intel.com>
Cc: Borislav Petkov <bp@suse.de>
Cc: Andi Kleen <ak@linux.intel.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Juergen Gross <jgross@suse.com>
Cc: dyoung@redhat.com
Cc: Eric Biederman <ebiederm@xmission.com>
Cc: kexec@lists.infradead.org
Link: http://lkml.kernel.org/r/1475514432-27682-1-git-send-email-prarit@redhat.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
- Switch to new CPU hotplug mechanism.
- Support driver_override in pciback.
- Require vector callback for HVM guests (the alternate mechanism via
the platform device has been broken for ages).
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJX9lkNAAoJEFxbo/MsZsTRnd8IAKnCH9pd2c1GgAPse2s8yBUL
jh/nTQh+niVvpFA9elpfz+TrAIu4P0KLcnx6jhZ0Uv+Cmeaz5Ps+IaqyXBmqmeCm
hjrnDo6wEVB/1LMtzibNk0hQcIN73MUEIfUESjl1iiIw3lPDPMIihMbpCAzVzaRf
M8sInTTwcx0A9njUijEwT1wKV45hM7bpnAufChkxk3V3G2+JxBDYAQJCfW0u1DjR
WFpbGKyNetXSVSf6QVZhW+lTnqTAUk0a5IqOg6UbzzbsHM7KgzwxB0FXYMRsL8jV
3VNiRJovNy+0F3T1VewPXWFlWs+QFK1GH0Hbncc5kUATNBm/VOjNt8H0dwUlfLM=
=n1rz
-----END PGP SIGNATURE-----
Merge tag 'for-linus-4.9-rc0-tag' of git://git.kernel.org/pub/scm/linux/kernel/git/xen/tip
Pull xen updates from David Vrabel:
"xen features and fixes for 4.9:
- switch to new CPU hotplug mechanism
- support driver_override in pciback
- require vector callback for HVM guests (the alternate mechanism via
the platform device has been broken for ages)"
* tag 'for-linus-4.9-rc0-tag' of git://git.kernel.org/pub/scm/linux/kernel/git/xen/tip:
xen/x86: Update topology map for PV VCPUs
xen/x86: Initialize per_cpu(xen_vcpu, 0) a little earlier
xen/pciback: support driver_override
xen/pciback: avoid multiple entries in slot list
xen/pciback: simplify pcistub device handling
xen: Remove event channel notification through Xen PCI platform device
xen/events: Convert to hotplug state machine
xen/x86: Convert to hotplug state machine
x86/xen: add missing \n at end of printk warning message
xen/grant-table: Use kmalloc_array() in arch_gnttab_valloc()
xen: Make VPMU init message look less scary
xen: rename xen_pmu_init() in sys-hypervisor.c
hotplug: Prevent alloc/free of irq descriptors during cpu up/down (again)
xen/x86: Move irq allocation from Xen smp_op.cpu_up()
All architectures:
Move `make kvmconfig` stubs from x86; use 64 bits for debugfs stats.
ARM:
Important fixes for not using an in-kernel irqchip; handle SError
exceptions and present them to guests if appropriate; proxying of GICV
access at EL2 if guest mappings are unsafe; GICv3 on AArch32 on ARMv8;
preparations for GICv3 save/restore, including ABI docs; cleanups and
a bit of optimizations.
MIPS:
A couple of fixes in preparation for supporting MIPS EVA host kernels;
MIPS SMP host & TLB invalidation fixes.
PPC:
Fix the bug which caused guests to falsely report lockups; other minor
fixes; a small optimization.
s390:
Lazy enablement of runtime instrumentation; up to 255 CPUs for nested
guests; rework of machine check deliver; cleanups and fixes.
x86:
IOMMU part of AMD's AVIC for vmexit-less interrupt delivery; Hyper-V
TSC page; per-vcpu tsc_offset in debugfs; accelerated INS/OUTS in
nVMX; cleanups and fixes.
-----BEGIN PGP SIGNATURE-----
iQEcBAABCAAGBQJX9iDrAAoJEED/6hsPKofoOPoIAIUlgojkb9l2l1XVDgsXdgQL
sRVhYSVv7/c8sk9vFImrD5ElOPZd+CEAIqFOu45+NM3cNi7gxip9yftUVs7wI5aC
eDZRWm1E4trDZLe54ZM9ThcqZzZZiELVGMfR1+ZndUycybwyWzafpXYsYyaXp3BW
hyHM3qVkoWO3dxBWFwHIoO/AUJrWYkRHEByKyvlC6KPxSdBPSa5c1AQwMCoE0Mo4
K/xUj4gBn9eMelNhg4Oqu/uh49/q+dtdoP2C+sVM8bSdquD+PmIeOhPFIcuGbGFI
B+oRpUhIuntN39gz8wInJ4/GRSeTuR2faNPxMn4E1i1u4LiuJvipcsOjPfe0a18=
=fZRB
-----END PGP SIGNATURE-----
Merge tag 'kvm-4.9-1' of git://git.kernel.org/pub/scm/virt/kvm/kvm
Pull KVM updates from Radim Krčmář:
"All architectures:
- move `make kvmconfig` stubs from x86
- use 64 bits for debugfs stats
ARM:
- Important fixes for not using an in-kernel irqchip
- handle SError exceptions and present them to guests if appropriate
- proxying of GICV access at EL2 if guest mappings are unsafe
- GICv3 on AArch32 on ARMv8
- preparations for GICv3 save/restore, including ABI docs
- cleanups and a bit of optimizations
MIPS:
- A couple of fixes in preparation for supporting MIPS EVA host
kernels
- MIPS SMP host & TLB invalidation fixes
PPC:
- Fix the bug which caused guests to falsely report lockups
- other minor fixes
- a small optimization
s390:
- Lazy enablement of runtime instrumentation
- up to 255 CPUs for nested guests
- rework of machine check deliver
- cleanups and fixes
x86:
- IOMMU part of AMD's AVIC for vmexit-less interrupt delivery
- Hyper-V TSC page
- per-vcpu tsc_offset in debugfs
- accelerated INS/OUTS in nVMX
- cleanups and fixes"
* tag 'kvm-4.9-1' of git://git.kernel.org/pub/scm/virt/kvm/kvm: (140 commits)
KVM: MIPS: Drop dubious EntryHi optimisation
KVM: MIPS: Invalidate TLB by regenerating ASIDs
KVM: MIPS: Split kernel/user ASID regeneration
KVM: MIPS: Drop other CPU ASIDs on guest MMU changes
KVM: arm/arm64: vgic: Don't flush/sync without a working vgic
KVM: arm64: Require in-kernel irqchip for PMU support
KVM: PPC: Book3s PR: Allow access to unprivileged MMCR2 register
KVM: PPC: Book3S PR: Support 64kB page size on POWER8E and POWER8NVL
KVM: PPC: Book3S: Remove duplicate setting of the B field in tlbie
KVM: PPC: BookE: Fix a sanity check
KVM: PPC: Book3S HV: Take out virtual core piggybacking code
KVM: PPC: Book3S: Treat VTB as a per-subcore register, not per-thread
ARM: gic-v3: Work around definition of gic_write_bpr1
KVM: nVMX: Fix the NMI IDT-vectoring handling
KVM: VMX: Enable MSR-BASED TPR shadow even if APICv is inactive
KVM: nVMX: Fix reload apic access page warning
kvmconfig: add virtio-gpu to config fragment
config: move x86 kvm_guest.config to a common location
arm64: KVM: Remove duplicating init code for setting VMID
ARM: KVM: Support vgic-v3
...
Early during boot topology_update_package_map() computes
logical_pkg_ids for all present processors.
Later, when processors are brought up, identify_cpu() updates
these values based on phys_pkg_id which is a function of
initial_apicid. On PV guests the latter may point to a
non-existing node, causing logical_pkg_ids to be set to -1.
Intel's RAPL uses logical_pkg_id (as topology_logical_package_id())
to index its arrays and therefore in this case will point to index
65535 (since logical_pkg_id is a u16). This could lead to either a
crash or may actually access random memory location.
As a workaround, we recompute topology during CPU bringup to reset
logical_pkg_id to a valid value.
(The reason for initial_apicid being bogus is because it is
initial_apicid of the processor from which the guest is launched.
This value is CPUID(1).EBX[31:24])
Signed-off-by: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Cc: stable@vger.kernel.org
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
When compiling on x86 with CONFIG_OPROFILE=m and CONFIG_FRAME_POINTER=n,
the oprofile module fails to link:
ERROR: ftrace_graph_ret_addr" [arch/x86/oprofile/oprofile.ko] undefined!
The problem was introduced when oprofile was converted to use the new
x86 unwinder. When frame pointers are disabled, the "guess" unwinder's
unwind_get_return_address() is an inline function which calls
ftrace_graph_ret_addr(), which is not exported.
Fix it by converting the "guess" version of unwind_get_return_address()
to an exported out-of-line function, just like its frame pointer
counterpart.
Reported-by: Karl Beldan <karl.beldan@gmail.com>
Signed-off-by: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: Frederic Weisbecker <fweisbec@gmail.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Fixes: ec2ad9ccf1 ("oprofile/x86: Convert x86_backtrace() to use the new unwinder")
Link: http://lkml.kernel.org/r/be08d589f6474df78364e081c42777e382af9352.1475731632.git.jpoimboe@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
* pci/host-vmd:
x86/PCI: VMD: Move VMD driver to drivers/pci/host
x86/PCI: VMD: Synchronize with RCU freeing MSI IRQ descs
x86/PCI: VMD: Eliminate index member from IRQ list
x86/PCI: VMD: Eliminate vmd_vector member from list type
x86/PCI: VMD: Convert to use pci_alloc_irq_vectors() API
x86/PCI: VMD: Allocate IRQ lists with correct MSI-X count
PCI: Use positive flags in pci_alloc_irq_vectors()
PCI: Update "pci=resource_alignment" documentation
Conflicts:
drivers/pci/host/Kconfig
drivers/pci/host/Makefile
In a virtualized environment the APIC timer calibration can go wrong when
the host is overcommitted or the guest is running nested. This results
in the APIC timers operating at an incorrect frequency.
Since VMware supports a mechanism to retrieve the local APIC frequency we
can ask the hypervisor for it and skip the APIC calibration loop.
Signed-off-by: Renat Valiullin <rvaliullin@vmware.com>
Acked-by: Alok N Kataria <akataria@vmware.com>
Cc: virtualization@lists.linux-foundation.org
Link: http://lkml.kernel.org/r/20161004201148.GA1421@uu64vm
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
xen_cpuhp_setup() calls mutex_lock() which, when CONFIG_DEBUG_MUTEXES
is defined, ends up calling xen_save_fl(). That routine expects
per_cpu(xen_vcpu, 0) to be already initialized.
Signed-off-by: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Reported-by: Sander Eikelenboom <linux@eikelenboom.it>
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
Move the driver source and Kconfig to the PCI host bridge drivers directory
and move the config option to a more appropriate sub-menu instead of
occupying the top-level location.
Update the Kconfig option with the X86_64 dependency that was implicitly
included from the previous location, and add information about the module
name when built as a loadable module.
Signed-off-by: Keith Busch <keith.busch@intel.com>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
CC: Jon Derrick <jonathan.derrick@intel.com>
When a CPU is about to be offlined we call fixup_irqs() that resets IRQ
affinities related to the CPU in question. The same thing is also done when
the system is suspended to S-states like S3 (mem).
For each IRQ we try to complete any on-going move regardless whether the
IRQ is actually part of x86_vector_domain. For each IRQ descriptor we fetch
its chip_data, assume it is of type struct apic_chip_data and manipulate it
by clearing old_domain mask etc. For irq_chips that are not part of the
x86_vector_domain, like those created by various GPIO drivers, will find
their chip_data being changed unexpectly.
Below is an example where GPIO chip owned by pinctrl-sunrisepoint.c gets
corrupted after resume:
# cat /sys/kernel/debug/gpio
gpiochip0: GPIOs 360-511, parent: platform/INT344B:00, INT344B:00:
gpio-511 ( |sysfs ) in hi
# rtcwake -s10 -mmem
<10 seconds passes>
# cat /sys/kernel/debug/gpio
gpiochip0: GPIOs 360-511, parent: platform/INT344B:00, INT344B:00:
gpio-511 ( |sysfs ) in ?
Note '?' in the output. It means the struct gpio_chip ->get function is
NULL whereas before suspend it was there.
Fix this by first checking that the IRQ belongs to x86_vector_domain before
we try to use the chip_data as struct apic_chip_data.
Reported-and-tested-by: Sakari Ailus <sakari.ailus@linux.intel.com>
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
Cc: stable@vger.kernel.org # 4.4+
Link: http://lkml.kernel.org/r/20161003101708.34795-1-mika.westerberg@linux.intel.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Pull CPU hotplug updates from Thomas Gleixner:
"Yet another batch of cpu hotplug core updates and conversions:
- Provide core infrastructure for multi instance drivers so the
drivers do not have to keep custom lists.
- Convert custom lists to the new infrastructure. The block-mq custom
list conversion comes through the block tree and makes the diffstat
tip over to more lines removed than added.
- Handle unbalanced hotplug enable/disable calls more gracefully.
- Remove the obsolete CPU_STARTING/DYING notifier support.
- Convert another batch of notifier users.
The relayfs changes which conflicted with the conversion have been
shipped to me by Andrew.
The remaining lot is targeted for 4.10 so that we finally can remove
the rest of the notifiers"
* 'smp-hotplug-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (46 commits)
cpufreq: Fix up conversion to hotplug state machine
blk/mq: Reserve hotplug states for block multiqueue
x86/apic/uv: Convert to hotplug state machine
s390/mm/pfault: Convert to hotplug state machine
mips/loongson/smp: Convert to hotplug state machine
mips/octeon/smp: Convert to hotplug state machine
fault-injection/cpu: Convert to hotplug state machine
padata: Convert to hotplug state machine
cpufreq: Convert to hotplug state machine
ACPI/processor: Convert to hotplug state machine
virtio scsi: Convert to hotplug state machine
oprofile/timer: Convert to hotplug state machine
block/softirq: Convert to hotplug state machine
lib/irq_poll: Convert to hotplug state machine
x86/microcode: Convert to hotplug state machine
sh/SH-X3 SMP: Convert to hotplug state machine
ia64/mca: Convert to hotplug state machine
ARM/OMAP/wakeupgen: Convert to hotplug state machine
ARM/shmobile: Convert to hotplug state machine
arm64/FP/SIMD: Convert to hotplug state machine
...
Pull x86 vdso updates from Ingo Molnar:
"The main changes in this cycle centered around adding support for
32-bit compatible C/R of the vDSO on 64-bit kernels, by Dmitry
Safonov"
* 'x86-vdso-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/vdso: Use CONFIG_X86_X32_ABI to enable vdso prctl
x86/vdso: Only define map_vdso_randomized() if CONFIG_X86_64
x86/vdso: Only define prctl_map_vdso() if CONFIG_CHECKPOINT_RESTORE
x86/signal: Add SA_{X32,IA32}_ABI sa_flags
x86/ptrace: Down with test_thread_flag(TIF_IA32)
x86/coredump: Use pr_reg size, rather that TIF_IA32 flag
x86/arch_prctl/vdso: Add ARCH_MAP_VDSO_*
x86/vdso: Replace calculate_addr in map_vdso() with addr
x86/vdso: Unmap vdso blob on vvar mapping failure
Pull x86 timer updates from Ingo Molnar:
"This tree includes a HPET overhead micro-optimization plus new TSC
frequencies for newer Intel CPUs"
* 'x86-timers-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/tsc: Add additional Intel CPU models to the crystal quirk list
x86/tsc: Use cpu id defines instead of hex constants
x86/hpet: Reduce HPET counter read contention
Pull x86 platform changes from Ingo Molnar:
"The main changes in this cycle were:
- SGI UV updates (Andrew Banman)
- Intel MID updates (Andy Shevchenko)
- Initial Mellanox systems platform (Vadim Pasternak)"
* 'x86-platform-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/platform/mellanox: Fix return value check in mlxplat_init()
x86/platform/mellanox: Introduce support for Mellanox systems platform
x86/platform/uv/BAU: Add UV4-specific functions
x86/platform/uv/BAU: Fix payload queue setup on UV4 hardware
x86/platform/uv/BAU: Disable software timeout on UV4 hardware
x86/platform/uv/BAU: Populate ->uvhub_version with UV4 version information
x86/platform/uv/BAU: Use generic function pointers
x86/platform/uv/BAU: Add generic function pointers
x86/platform/uv/BAU: Convert uv_physnodeaddr() use to uv_gpa_to_offset()
x86/platform/uv/BAU: Clean up pq_init()
x86/platform/uv/BAU: Clean up and update printks
x86/platform/uv/BAU: Clean up vertical alignment
x86/platform/intel-mid: Keep SRAM powered on at boot
x86/platform/intel-mid: Add Intel Penwell to ID table
x86/cpu: Rename Merrifield2 to Moorefield
x86/platform/intel-mid: Implement power off sequence
x86/platform/intel-mid: Enable SD card detection on Merrifield
x86/platform/intel-mid: Enable WiFi on Intel Edison
x86/platform/intel-mid: Run PWRMU command immediately
Pull x86 cleanups from Ingo Molnar:
"Header file and a wrapper functions cleanup"
* 'x86-cleanups-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86: Migrate exception table users off module.h and onto extable.h
x86: Clean up various simple wrapper functions
Pull x86 boot updates from Ingo Molnar:
"The changes in this cycle were:
- Save e820 table RAM footprint on larger kernel configurations.
(Denys Vlasenko)
- pmem related fixes (Dan Williams)
- theoretical e820 boundary condition fix (Wei Yang)"
* 'x86-boot-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/boot: Fix kdump, cleanup aborted E820_PRAM max_pfn manipulation
x86/e820: Use much less memory for e820/e820_saved, save up to 120k
x86/e820: Prepare e280 code for switch to dynamic storage
x86/e820: Mark some static functions __init
x86/e820: Fix very large 'size' handling boundary condition
Pull low-level x86 updates from Ingo Molnar:
"In this cycle this topic tree has become one of those 'super topics'
that accumulated a lot of changes:
- Add CONFIG_VMAP_STACK=y support to the core kernel and enable it on
x86 - preceded by an array of changes. v4.8 saw preparatory changes
in this area already - this is the rest of the work. Includes the
thread stack caching performance optimization. (Andy Lutomirski)
- switch_to() cleanups and all around enhancements. (Brian Gerst)
- A large number of dumpstack infrastructure enhancements and an
unwinder abstraction. The secret long term plan is safe(r) live
patching plus maybe another attempt at debuginfo based unwinding -
but all these current bits are standalone enhancements in a frame
pointer based debug environment as well. (Josh Poimboeuf)
- More __ro_after_init and const annotations. (Kees Cook)
- Enable KASLR for the vmemmap memory region. (Thomas Garnier)"
[ The virtually mapped stack changes are pretty fundamental, and not
x86-specific per se, even if they are only used on x86 right now. ]
* 'x86-asm-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (70 commits)
x86/asm: Get rid of __read_cr4_safe()
thread_info: Use unsigned long for flags
x86/alternatives: Add stack frame dependency to alternative_call_2()
x86/dumpstack: Fix show_stack() task pointer regression
x86/dumpstack: Remove dump_trace() and related callbacks
x86/dumpstack: Convert show_trace_log_lvl() to use the new unwinder
oprofile/x86: Convert x86_backtrace() to use the new unwinder
x86/stacktrace: Convert save_stack_trace_*() to use the new unwinder
perf/x86: Convert perf_callchain_kernel() to use the new unwinder
x86/unwind: Add new unwind interface and implementations
x86/dumpstack: Remove NULL task pointer convention
fork: Optimize task creation by caching two thread stacks per CPU if CONFIG_VMAP_STACK=y
sched/core: Free the stack early if CONFIG_THREAD_INFO_IN_TASK
lib/syscall: Pin the task stack in collect_syscall()
x86/process: Pin the target stack in get_wchan()
x86/dumpstack: Pin the target stack when dumping it
kthread: Pin the stack via try_get_task_stack()/put_task_stack() in to_live_kthread() function
sched/core: Add try_get_task_stack() and put_task_stack()
x86/entry/64: Fix a minor comment rebase error
iommu/amd: Don't put completion-wait semaphore on stack
...
Pull x86 apic updates from Ingo Molnar:
"The main changes are:
- Persistent CPU/node numbering across CPU hotplug/unplug events.
This is a pretty involved series of changes that first fetches all
the information during bootup and then uses it for the various
hotplug/unplug methods. (Gu Zheng, Dou Liyang)
- IO-APIC hot-add/remove fixes and enhancements. (Rui Wang)
- ... various fixes, cleanups and enhancements"
* 'x86-apic-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (22 commits)
x86/apic: Fix silent & fatal merge conflict in __generic_processor_info()
acpi: Fix broken error check in map_processor()
acpi: Validate processor id when mapping the processor
acpi: Provide mechanism to validate processors in the ACPI tables
x86/acpi: Set persistent cpuid <-> nodeid mapping when booting
x86/acpi: Enable MADT APIs to return disabled apicids
x86/acpi: Introduce persistent storage for cpuid <-> apicid mapping
x86/acpi: Enable acpi to register all possible cpus at boot time
x86/numa: Online memory-less nodes at boot time
x86/apic: Get rid of apic_version[] array
x86/apic: Order irq_enter/exit() calls correctly vs. ack_APIC_irq()
x86/ioapic: Ignore root bridges without a companion ACPI device
x86/apic: Update comment about disabling processor focus
x86/smpboot: Check APIC ID before setting up default routing
x86/ioapic: Fix IOAPIC failing to request resource
x86/ioapic: Fix lost IOAPIC resource after hot-removal and hotadd
x86/ioapic: Fix setup_res() failing to get resource
x86/ioapic: Support hot-removal of IOAPICs present during boot
x86/ioapic: Change prototype of acpi_ioapic_add()
x86/apic, ACPI: Fix incorrect assignment when handling apic/x2apic entries
...
Pull RAS updates from Ingo Molnar:
"The main changes were:
- Lots of enhancements for AMD SMCA (Scalable MCA
features/extensions) systems: extract, decode and print more
hardware error information and add matching support on the
injection/testing side as well. (Yazn Ghannam)
- Various MCE handling improvements on modern Intel Xeons. (Tony
Luck)
- Plus misc fixes and enhancements"
* 'ras-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (21 commits)
x86/RAS/mce_amd_inj: Remove debugfs dir recursively on exit
x86/RAS/mce_amd_inj: Fix signed wrap around when decrementing index 'i'
x86/RAS/mce_amd_inj: Fix some W= warnings
x86/MCE/AMD, EDAC: Handle reserved bank 4 on Fam17h properly
x86/mce/AMD: Extract the error address on SMCA systems
x86/mce, EDAC/mce_amd: Print MCA_SYND and MCA_IPID during MCE on SMCA systems
x86/mce/AMD: Save MCA_IPID in MCE struct on SMCA systems
x86/mce/AMD: Ensure the deferred error interrupt is of type APIC on SMCA systems
x86/mce/AMD: Update sysfs bank names for SMCA systems
x86/mce/AMD, EDAC/mce_amd: Define and use tables for known SMCA IP types
EDAC/mce_amd: Use SMCA prefix for error descriptions arrays
EDAC/mce_amd: Add missing SMCA error descriptions
x86/mce/AMD: Read MSRs on the CPU allocating the threshold blocks
x86/RAS: Add syndrome support to mce_amd_inj
EDAC/mce_amd: Print syndrome register value on SMCA systems
x86/mce: Add support for new MCA_SYND register
x86/mce/AMD: Use msr_ops.misc() in allocate_threshold_blocks()
x86/mce: Drop X86_FEATURE_MCE_RECOVERY and the related model string test
x86/mce: Improve memcpy_mcsafe()
x86/mce: Add PCI quirks to identify Xeons with machine check recovery
...
Pull perf updates from Ingo Molnar:
"The main kernel side changes were:
- uprobes enhancements (Masami Hiramatsu)
- Uncore group events enhancements (David Carrillo-Cisneros)
- x86 Intel: Add support for Skylake server uncore PMUs (Kan Liang)
- x86 Intel: LBR cleanups and enhancements, for better branch
annotation tracking (Peter Zijlstra)
- x86 Intel: Add support for PTWRITE and power event tracing
(Alexander Shishkin)
- ... various fixes, cleanups and smaller enhancements.
Lots of tooling changes - a couple of highlights:
- Support event group view with hierarchy mode in 'perf top' and
'perf report' (Namhyung Kim)
e.g.:
$ perf record -e '{cycles,instructions}' make
$ perf report --hierarchy --stdio
...
# Overhead Command / Shared Object / Symbol
# ...................... ..................................
...
25.74% 27.18%sh
19.96% 24.14%libc-2.24.so
9.55% 14.64%[.] __strcmp_sse2
1.54% 0.00%[.] __tfind
1.07% 1.13%[.] _int_malloc
0.95% 0.00%[.] __strchr_sse2
0.89% 1.39%[.] __tsearch
0.76% 0.00%[.] strlen
- Add branch stack / basic block info to 'perf annotate --stdio',
where for each branch, we add an asm comment after the instruction
with information on how often it was taken and predicted. See
example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Add support for using symbols in address filters with Intel PT and
ARM CoreSight (hardware assisted tracing facilities) (Adrian
Hunter, Mathieu Poirier)
- Add support for interacting with Coresight PMU ETMs/PTMs, that are
IP blocks to perform hardware assisted tracing on a ARM CPU core
(Mathieu Poirier)
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Allow configuring the default 'perf report -s' sort order in
~/.perfconfig, for instance, "sym,dso" may be more fitting for
kernel developers. (Arnaldo Carvalho de Melo)
- ... plus lots of other changes, refactorings, features and fixes"
* 'perf-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (149 commits)
perf tests: Add dwarf unwind test for powerpc
perf probe: Match linkage name with mangled name
perf probe: Fix to cut off incompatible chars from group name
perf probe: Skip if the function address is 0
perf probe: Ignore the error of finding inline instance
perf intel-pt: Fix decoding when there are address filters
perf intel-pt: Enable decoder to handle TIP.PGD with missing IP
perf intel-pt: Read address filter from AUXTRACE_INFO event
perf intel-pt: Record address filter in AUXTRACE_INFO event
perf intel-pt: Add a helper function for processing AUXTRACE_INFO
perf intel-pt: Fix missing error codes processing auxtrace_info
perf intel-pt: Add support for recording the max non-turbo ratio
perf intel-pt: Fix snapshot overlap detection decoder errors
perf probe: Increase debug level of SDT debug messages
perf record: Add support for using symbols in address filters
perf symbols: Add dso__last_symbol()
perf record: Fix error paths
perf record: Rename label 'out_symbol_exit'
perf script: Fix vanished idle symbols
perf evsel: Add support for address filters
...
Pull locking updates from Ingo Molnar:
"The main changes in this cycle were:
- rwsem micro-optimizations (Davidlohr Bueso)
- Improve the implementation and optimize the performance of
percpu-rwsems. (Peter Zijlstra.)
- Convert all lglock users to better facilities such as percpu-rwsems
or percpu-spinlocks and remove lglocks. (Peter Zijlstra)
- Remove the ticket (spin)lock implementation. (Peter Zijlstra)
- Korean translation of memory-barriers.txt and related fixes to the
English document. (SeongJae Park)
- misc fixes and cleanups"
* 'locking-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (24 commits)
x86/cmpxchg, locking/atomics: Remove superfluous definitions
x86, locking/spinlocks: Remove ticket (spin)lock implementation
locking/lglock: Remove lglock implementation
stop_machine: Remove stop_cpus_lock and lg_double_lock/unlock()
fs/locks: Use percpu_down_read_preempt_disable()
locking/percpu-rwsem: Add down_read_preempt_disable()
fs/locks: Replace lg_local with a per-cpu spinlock
fs/locks: Replace lg_global with a percpu-rwsem
locking/percpu-rwsem: Add DEFINE_STATIC_PERCPU_RWSEMand percpu_rwsem_assert_held()
locking/pv-qspinlock: Use cmpxchg_release() in __pv_queued_spin_unlock()
locking/rwsem, x86: Drop a bogus cc clobber
futex: Add some more function commentry
locking/hung_task: Show all locks
locking/rwsem: Scan the wait_list for readers only once
locking/rwsem: Remove a few useless comments
locking/rwsem: Return void in __rwsem_mark_wake()
locking, rcu, cgroup: Avoid synchronize_sched() in __cgroup_procs_write()
locking/Documentation: Add Korean translation
locking/Documentation: Fix a typo of example result
locking/Documentation: Fix wrong section reference
...
Pull EFI updates from Ingo Molnar:
"Main changes in this cycle were:
- Refactor the EFI memory map code into architecture neutral files
and allow drivers to permanently reserve EFI boot services regions
on x86, as well as ARM/arm64. (Matt Fleming)
- Add ARM support for the EFI ESRT driver. (Ard Biesheuvel)
- Make the EFI runtime services and efivar API interruptible by
swapping spinlocks for semaphores. (Sylvain Chouleur)
- Provide the EFI identity mapping for kexec which allows kexec to
work on SGI/UV platforms with requiring the "noefi" kernel command
line parameter. (Alex Thorlton)
- Add debugfs node to dump EFI page tables on arm64. (Ard Biesheuvel)
- Merge the EFI test driver being carried out of tree until now in
the FWTS project. (Ivan Hu)
- Expand the list of flags for classifying EFI regions as "RAM" on
arm64 so we align with the UEFI spec. (Ard Biesheuvel)
- Optimise out the EFI mixed mode if it's unsupported (CONFIG_X86_32)
or disabled (CONFIG_EFI_MIXED=n) and switch the early EFI boot
services function table for direct calls, alleviating us from
having to maintain the custom function table. (Lukas Wunner)
- Miscellaneous cleanups and fixes"
* 'efi-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (30 commits)
x86/efi: Round EFI memmap reservations to EFI_PAGE_SIZE
x86/efi: Allow invocation of arbitrary boot services
x86/efi: Optimize away setup_gop32/64 if unused
x86/efi: Use kmalloc_array() in efi_call_phys_prolog()
efi/arm64: Treat regions with WT/WC set but WB cleared as memory
efi: Add efi_test driver for exporting UEFI runtime service interfaces
x86/efi: Defer efi_esrt_init until after memblock_x86_fill
efi/arm64: Add debugfs node to dump UEFI runtime page tables
x86/efi: Remove unused find_bits() function
fs/efivarfs: Fix double kfree() in error path
x86/efi: Map in physical addresses in efi_map_region_fixed
lib/ucs2_string: Speed up ucs2_utf8size()
firmware-gsmi: Delete an unnecessary check before the function call "dma_pool_destroy"
x86/efi: Initialize status to ensure garbage is not returned on small size
efi: Replace runtime services spinlock with semaphore
efi: Don't use spinlocks for efi vars
efi: Use a file local lock for efivars
efi/arm*: esrt: Add missing call to efi_esrt_init()
efi/esrt: Use memremap not ioremap to access ESRT table in memory
x86/efi-bgrt: Use efi_mem_reserve() to avoid copying image data
...
Pull core SMP updates from Ingo Molnar:
"Two main change is generic vCPU pinning and physical CPU SMP-call
support, for Xen to be able to perform certain calls on specific
physical CPUs - by Juergen Gross"
* 'core-smp-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
smp: Allocate smp_call_on_cpu() workqueue on stack too
hwmon: Use smp_call_on_cpu() for dell-smm i8k
dcdbas: Make use of smp_call_on_cpu()
xen: Add xen_pin_vcpu() to support calling functions on a dedicated pCPU
smp: Add function to execute a function synchronously on a CPU
virt, sched: Add generic vCPU pinning support
xen: Sync xen header
- Update of the ACPICA code in the kernel to upstream revision 20160831 with
the following major changes:
* New mechanism for GPE masking.
* Fixes for issues related to the LoadTable operator and table loading.
* Fixes for issues related to so-called module-level code (MLC), that is
AML that doesn't belong to any methods.
* Change of the return value of the _OSI method to reflect the Windows
behavior.
* GAS (Generic Address Structure) support fix related to 32-bit FADT
addresses.
* Elimination of unnecessary FADT version 2 support.
* ACPI tools fixes and cleanups.
From Bob Moore, Lv Zheng, and Jung-uk Kim.
- ACPI sysfs interface updates to fix GPE handling (on top of the new GPE
masking mechanism in ACPICA) and issues related to table loading (Lv Zheng).
- New watchdog driver based on the ACPI WDAT (ACPI Watchdog Action Table),
needed on some platforms to replace the iTCO watchdog that doesn't work there
and related updates of the intel_pmc_ipc, i2c/i801 and MFD/lcp_ich drivers
(Mika Westerberg).
- Driver core fix to prevent it from leaking secondary fwnode objects during
device removal (Lukas Wunner).
- New definitions of built-in properties for UART in ACPI-based x86 SoC drivers
and a 8250_dw driver quirk for the APM X-Gene SoC (Heikki Krogerus).
- New device ID for the Vulcan SPI controller and constification of local
strucures in the AMD SoC (APD) ACPI driver (Kamlakant Patel, Julia Lawall).
- Fix for a bug causing the allocation of PCI resorces to fail if
ACPI-enumerated child platform devices are registered below the PCI
devices in question (Mika Westerberg).
- Change of the default polarity for PCI legacy IRQs to high on systems
booting wth ACPI on platforms with a GIC interrupt controller model
fixing the discrepancy between the specification and HW behavior (Lorenzo
Pieralisi).
- Fixes for the handling of system suspend/resume in the ACPI EC driver and
update of that driver to make it cope with the cases when the EC device
defined in the ECDT has to be used throughout the entire system life cycle
(Lv Zheng).
- Update of the ACPI CPPC library to allow it to batch requests sent over the
PCC channel (to reduce overhead), to support the fixed functional hardware
(FFH) CPPC registers access type, to notify the mailbox framework about TX
completions when the interrupt flag is set for the PCC mailbox, and to
support HW-Reduced Communication Subspace type 2 (Ashwin Chaugule, Prashanth
Prakash, Srinivas Pandruvada, Hoan Tran).
- ACPI button driver fix and documentation update related to the handling of
laptop lids (Lv Zheng).
- ACPI battery driver initialization fix (Carlos Garnacho).
- ACPI GPIO enumeration documentation update (Mika Westerberg).
- Assorted updates of the core ACPI bus type code (Lukas Wunner, Lv Zheng).
- Assorted cleanups of the ACPI table parsing code and the x86-specific ACPI
code (Al Stone).
- Fixes for assorted ACPI-related issues found in linux-next (Wei Yongjun).
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2.0.22 (GNU/Linux)
iQIcBAABCAAGBQJX8Y5+AAoJEILEb/54YlRx73oP/RiAi86NKjOj+GfYceVe37jn
6lSqoMugjgTQHRYvYiQCjJ/BR0GzQZqUkz9TAu1Op14+rhTH3OhSfPizzJWCpVfA
G9l9ZRQNnsKNs14bbYmWtmWduh46dFLVFJqo+M/0H3ZMFZu6Adcb+1SBtXHUoQ6L
z69ngFxTu3yRvqS4cmm5h7SOx5W2uZZl8zViJW8jgyGhUBStG87gzR6wsYBldGCk
XFxcaGWBXRccWGAQLSwfs0psQccEooCqbpsDqaUdrK/mI0rsQr88f25ZxEE7Zw7H
bv3py1cgJBZRq36L7eBGQXjIE7YQey6qG2lug2zsUJWe+vzy2vHjHVJHuBXKKgv3
txOA6QZx63UgEyN3zFT7K5ek6uOnkKdeE+s+Laj+K/x4V2R6gbtgO011EVcXy+bI
NvqsO76tfPHpwrn5s1VVc5lcEBEPHKHb+WulHrqhSSU4ivk0gtJDeSI+c8xta6YT
XwSry5tozDLkG1uEZqkyY1XTlOUAHO8E6YcrlOv2z1+mG7L8OH/vCp1apzgexsZA
1683AH5cwKc3KaP+4QdKGdxY2BDxb7OTVh3cGy4kAYb6tqQ/vj7vlRiJvtaMBtFw
xJn3buuagwJzKtgebpA565opvyFAfUX/RNFlTP63aXAefSAgq6KLq70vKFxkIZto
H1LpUbmiEbuBml8CBGb1
=xDOQ
-----END PGP SIGNATURE-----
Merge tag 'acpi-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm
Pull ACPI updates from Rafael Wysocki:
"First off, the ACPICA code in the kernel is updated to upstream
revision 20160831 that brings in a few bug fixes and cleanups. In
particular, it is possible to mask GPEs now (and the sysfs interface
for GPE control is fixed on top of that), problems related to the
table loading mechanism are fixed and all code related to FADT version
2 (which has never been part of the ACPI specification) is dropped.
On the new features front, there is a new watchdog driver based on the
ACPI WDAT (ACPI Watchdog Action Table), needed on some platforms to
replace the iTCO watchdog that doesn't work there, and some UART
devices get new definitions of built-in properties (to be accessed via
the generic device properties API).
Also, included is a fix for an ACPI-related PCI resorces allocation
issue and a few problems in the EC driver and in the button and
battery drivers are fixed.
In addition to that, the ACPI CPPC library is updated to make batching
of requests sent over the PCC channel possible (which reduces the PCC
usage overhead substantially in some cases) and to support functional
fixed hardware (FFH) type of CPPC registers access (which will allow
CPPC to be used on x86 too in the future).
As usual, there are some assorted fixes and cleanups too.
Specifics:
- Update of the ACPICA code in the kernel to upstream revision
20160831 with the following major changes:
* New mechanism for GPE masking.
* Fixes for issues related to the LoadTable operator and table
loading.
* Fixes for issues related to so-called module-level code (MLC),
that is AML that doesn't belong to any methods.
* Change of the return value of the _OSI method to reflect the
Windows behavior.
* GAS (Generic Address Structure) support fix related to 32-bit
FADT addresses.
* Elimination of unnecessary FADT version 2 support.
* ACPI tools fixes and cleanups.
From Bob Moore, Lv Zheng, and Jung-uk Kim.
- ACPI sysfs interface updates to fix GPE handling (on top of the new
GPE masking mechanism in ACPICA) and issues related to table
loading (Lv Zheng).
- New watchdog driver based on the ACPI WDAT (ACPI Watchdog Action
Table), needed on some platforms to replace the iTCO watchdog that
doesn't work there and related updates of the intel_pmc_ipc,
i2c/i801 and MFD/lcp_ich drivers (Mika Westerberg).
- Driver core fix to prevent it from leaking secondary fwnode objects
during device removal (Lukas Wunner).
- New definitions of built-in properties for UART in ACPI-based x86
SoC drivers and a 8250_dw driver quirk for the APM X-Gene SoC
(Heikki Krogerus).
- New device ID for the Vulcan SPI controller and constification of
local strucures in the AMD SoC (APD) ACPI driver (Kamlakant Patel,
Julia Lawall).
- Fix for a bug causing the allocation of PCI resorces to fail if
ACPI-enumerated child platform devices are registered below the PCI
devices in question (Mika Westerberg).
- Change of the default polarity for PCI legacy IRQs to high on
systems booting wth ACPI on platforms with a GIC interrupt
controller model fixing the discrepancy between the specification
and HW behavior (Lorenzo Pieralisi).
- Fixes for the handling of system suspend/resume in the ACPI EC
driver and update of that driver to make it cope with the cases
when the EC device defined in the ECDT has to be used throughout
the entire system life cycle (Lv Zheng).
- Update of the ACPI CPPC library to allow it to batch requests sent
over the PCC channel (to reduce overhead), to support the fixed
functional hardware (FFH) CPPC registers access type, to notify the
mailbox framework about TX completions when the interrupt flag is
set for the PCC mailbox, and to support HW-Reduced Communication
Subspace type 2 (Ashwin Chaugule, Prashanth Prakash, Srinivas
Pandruvada, Hoan Tran).
- ACPI button driver fix and documentation update related to the
handling of laptop lids (Lv Zheng).
- ACPI battery driver initialization fix (Carlos Garnacho).
- ACPI GPIO enumeration documentation update (Mika Westerberg).
- Assorted updates of the core ACPI bus type code (Lukas Wunner, Lv
Zheng).
- Assorted cleanups of the ACPI table parsing code and the
x86-specific ACPI code (Al Stone).
- Fixes for assorted ACPI-related issues found in linux-next (Wei
Yongjun)"
* tag 'acpi-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm: (98 commits)
ACPI / documentation: Use recommended name in GPIO property names
watchdog: wdat_wdt: Fix warning for using 0 as NULL
watchdog: wdat_wdt: fix return value check in wdat_wdt_probe()
platform/x86: intel_pmc_ipc: Do not create iTCO watchdog when WDAT table exists
i2c: i801: Do not create iTCO watchdog when WDAT table exists
mfd: lpc_ich: Do not create iTCO watchdog when WDAT table exists
ACPI / bus: Adjust ACPI subsystem initialization for new table loading mode
ACPICA: Parser: Fix a regression in LoadTable support
ACPICA: Tables: Fix "UNLOAD" code path lock issues
ACPI / watchdog: Add support for WDAT hardware watchdog
ACPI / platform: Pay attention to parent device's resources
PCI: Add pci_find_resource()
ACPI / CPPC: Support PCC with interrupt flag
ACPI / sysfs: Update sysfs signature handling code
ACPI / sysfs: Fix an issue for LoadTable opcode
ACPICA: Tables: Fix a regression in acpi_tb_find_table()
ACPI / tables: Remove duplicated include from tables.c
ACPI / APD: constify local structures
x86: ACPI: make variable names clearer in acpi_parse_madt_lapic_entries()
x86: ACPI: remove extraneous white space after semicolon
...
* acpi-x86:
x86: ACPI: make variable names clearer in acpi_parse_madt_lapic_entries()
x86: ACPI: remove extraneous white space after semicolon
* acpi-cppc:
ACPI / CPPC: Support PCC with interrupt flag
ACPI / CPPC: Add prefix cppc to cpudata structure name
ACPI / CPPC: Add support for functional fixed hardware address
ACPI / CPPC: Don't return on CPPC probe failure
ACPI / CPPC: Allow build with ACPI_CPU_FREQ_PSS config
ACPI / CPPC: check for error bit in PCC status field
ACPI / CPPC: move all PCC related information into pcc_data
ACPI / CPPC: add sysfs support to compute delivered performance
ACPI / CPPC: set a non-zero value for transition_latency
ACPI / CPPC: support for batching CPPC requests
ACPI / CPPC: acquire pcc_lock only while accessing PCC subspace
ACPI / CPPC: restructure read/writes for efficient sys mapped reg ops
mailbox: pcc: Support HW-Reduced Communication Subspace type 2
* acpi-soc:
ACPI / APD: constify local structures
ACPI / APD: Add device HID for Vulcan SPI controller
This warning:
WARNING: CPU: 0 PID: 3331 at arch/x86/entry/common.c:45 enter_from_user_mode+0x32/0x50
CPU: 0 PID: 3331 Comm: ldt_gdt_64 Not tainted 4.8.0-rc7+ #13
Call Trace:
dump_stack+0x99/0xd0
__warn+0xd1/0xf0
warn_slowpath_null+0x1d/0x20
enter_from_user_mode+0x32/0x50
error_entry+0x6d/0xc0
? general_protection+0x12/0x30
? native_load_gs_index+0xd/0x20
? do_set_thread_area+0x19c/0x1f0
SyS_set_thread_area+0x24/0x30
do_int80_syscall_32+0x7c/0x220
entry_INT80_compat+0x38/0x50
... can be reproduced by running the GS testcase of the ldt_gdt test unit in
the x86 selftests.
do_int80_syscall_32() will call enter_form_user_mode() to convert context
tracking state from user state to kernel state. The load_gs_index() call
can fail with user gsbase, gsbase will be fixed up and proceed if this
happen.
However, enter_from_user_mode() will be called again in the fixed up path
though it is context tracking kernel state currently.
This patch fixes it by just fixing up gsbase and telling lockdep that IRQs
are off once load_gs_index() failed with user gsbase.
Signed-off-by: Wanpeng Li <wanpeng.li@hotmail.com>
Acked-by: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/1475197266-3440-1-git-send-email-wanpeng.li@hotmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Otherwise arch_task_struct_size == 0 and we die. While we're at it,
set X86_FEATURE_ALWAYS, too.
Reported-by: David Saggiorato <david@saggiorato.net>
Tested-by: David Saggiorato <david@saggiorato.net>
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Dave Hansen <dave@sr71.net>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: stable@vger.kernel.org
Fixes: aaeb5c01c5b ("x86/fpu, sched: Introduce CONFIG_ARCH_WANTS_DYNAMIC_TASK_STRUCT and use it on x86")
Link: http://lkml.kernel.org/r/8de723afbf0811071185039f9088733188b606c9.1475103911.git.luto@kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Ever since commit 254d1a3f02 ("xen/pv-on-hvm kexec: shutdown watches
from old kernel") using the INTx interrupt from Xen PCI platform
device for event channel notification would just lockup the guest
during bootup. postcore_initcall now calls xs_reset_watches which
will eventually try to read a value from XenStore and will get stuck
on read_reply at XenBus forever since the platform driver is not
probed yet and its INTx interrupt handler is not registered yet. That
means that the guest can not be notified at this moment of any pending
event channels and none of the per-event handlers will ever be invoked
(including the XenStore one) and the reply will never be picked up by
the kernel.
The exact stack where things get stuck during xenbus_init:
-xenbus_init
-xs_init
-xs_reset_watches
-xenbus_scanf
-xenbus_read
-xs_single
-xs_single
-xs_talkv
Vector callbacks have always been the favourite event notification
mechanism since their introduction in commit 38e20b07ef ("x86/xen:
event channels delivery on HVM.") and the vector callback feature has
always been advertised for quite some time by Xen that's why INTx was
broken for several years now without impacting anyone.
Luckily this also means that event channel notification through INTx
is basically dead-code which can be safely removed without impacting
anybody since it has been effectively disabled for more than 4 years
with nobody complaining about it (at least as far as I'm aware of).
This commit removes event channel notification through Xen PCI
platform device.
Cc: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Cc: David Vrabel <david.vrabel@citrix.com>
Cc: Juergen Gross <jgross@suse.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Ingo Molnar <mingo@redhat.com>
Cc: "H. Peter Anvin" <hpa@zytor.com>
Cc: x86@kernel.org
Cc: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Cc: Bjorn Helgaas <bhelgaas@google.com>
Cc: Stefano Stabellini <stefano.stabellini@eu.citrix.com>
Cc: Julien Grall <julien.grall@citrix.com>
Cc: Vitaly Kuznetsov <vkuznets@redhat.com>
Cc: Paul Gortmaker <paul.gortmaker@windriver.com>
Cc: Ross Lagerwall <ross.lagerwall@citrix.com>
Cc: xen-devel@lists.xenproject.org
Cc: linux-kernel@vger.kernel.org
Cc: linux-pci@vger.kernel.org
Cc: Anthony Liguori <aliguori@amazon.com>
Signed-off-by: KarimAllah Ahmed <karahmed@amazon.de>
Reviewed-by: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
We use __read_cr4() vs __read_cr4_safe() inconsistently. On
CR4-less CPUs, all CR4 bits are effectively clear, so we can make
the code simpler and more robust by making __read_cr4() always fix
up faults on 32-bit kernels.
This may fix some bugs on old 486-like CPUs, but I don't have any
easy way to test that.
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Borislav Petkov <bp@alien8.de>
Cc: david@saggiorato.net
Link: http://lkml.kernel.org/r/ea647033d357d9ce2ad2bbde5a631045f5052fb6.1475178370.git.luto@kernel.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
We need to call GET_LE to read hdr->e_type.
Fixes: 57f90c3dfc ("x86/vdso: Error out if the vDSO isn't a valid DSO")
Reported-by: Paul Gortmaker <paul.gortmaker@windriver.com>
Signed-off-by: Segher Boessenkool <segher@kernel.crashing.org>
Acked-by: Andy Lutomirski <luto@kernel.org>
Cc: Stephen Rothwell <sfr@canb.auug.org.au>
Cc: linux-next@vger.kernel.org
Link: http://lkml.kernel.org/r/20160929193442.GA16617@gate.crashing.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
The condition for reading CR4 was wrong: there are some CPUs with
CPUID but not CR4. Rather than trying to make the condition exact,
use __read_cr4_safe().
Fixes: 18bc7bd523 ("x86/boot: Synchronize trampoline_cr4_features and mmu_cr4_features directly")
Reported-by: david@saggiorato.net
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Reviewed-by: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Link: http://lkml.kernel.org/r/8c453a61c4f44ab6ff43c29780ba04835234d2e5.1475178369.git.luto@kernel.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Switch to new CPU hotplug infrastructure.
Signed-off-by: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Suggested-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
The message is missing a \n, add it.
Signed-off-by: Colin Ian King <colin.king@canonical.com>
Reviewed-by: Juergen Gross <jgross@suse.com>
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
cmpxchg contained definitions for unused (x)add_* operations, dating back
to the original ticket spinlock implementation. Nowadays these are
unused so remove them.
Signed-off-by: Nikolay Borisov <n.borisov.lkml@gmail.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Paul E. McKenney <paulmck@linux.vnet.ibm.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: hpa@zytor.com
Link: http://lkml.kernel.org/r/1474913478-17757-1-git-send-email-n.borisov.lkml@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Current code can call set_cpu_sibling_map() and invoke sched_set_topology()
more than once (e.g. on CPU hot plug). When this happens after
sched_init_smp() has been called, we lose the NUMA topology extension to
sched_domain_topology in sched_init_numa(). This results in incorrect
topology when the sched domain is rebuilt.
This patch fixes the bug and issues warning if we call sched_set_topology()
after sched_init_smp().
Signed-off-by: Tim Chen <tim.c.chen@linux.intel.com>
Signed-off-by: Srinivas Pandruvada <srinivas.pandruvada@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: bp@suse.de
Cc: jolsa@redhat.com
Cc: rjw@rjwysocki.net
Link: http://lkml.kernel.org/r/1474485552-141429-2-git-send-email-srinivas.pandruvada@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
As EBS does not mean anything reasonable in the context it is used, it
seems like a misspelling for EBX.
Signed-off-by: Nicolas Iooss <nicolas.iooss_linux@m4x.org>
Acked-by: Borislav Petkov <bp@suse.de>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
-----BEGIN PGP SIGNATURE-----
iQEcBAABAgAGBQJX6H4uAAoJEHm+PkMAQRiG5sMH/3yzrMiUCSokdS+cvY+jgKAG
JS58JmRvBPz2mRaU3MRPBGRDeCz/Nc9LggL2ZcgM+E1ZYirlYyQfIED3lkqk5R07
kIN1wmb+kQhXyU4IY3fEX7joqyKC6zOy4DUChPkBQU0/0+VUmdVmcJvsuPlnMZtf
g95m0BdYTui+eDezASRqOEp3Lb5ONL4c3ao4yBP0LHF033ctj3VJQiyi5uERPZJ0
5e6Mo7Wxn78t9WqJLQAiEH46kTwT2plNlxf3XXqTenfIdbWhqE873HPGeSMa3VQV
VywXTpCpSPQsA8BYg66qIbebdKOhs9MOviHVfqDtwQlvwhjlBDya0gNHfI5fSy4=
=Y/L5
-----END PGP SIGNATURE-----
Merge tag 'v4.8-rc8' into drm-next
Linux 4.8-rc8
There was a lot of fallout in the imx/amdgpu/i915 drivers, so backmerge
it now to avoid troubles.
* tag 'v4.8-rc8': (1442 commits)
Linux 4.8-rc8
fault_in_multipages_readable() throws set-but-unused error
mm: check VMA flags to avoid invalid PROT_NONE NUMA balancing
radix tree: fix sibling entry handling in radix_tree_descend()
radix tree test suite: Test radix_tree_replace_slot() for multiorder entries
fix memory leaks in tracing_buffers_splice_read()
tracing: Move mutex to protect against resetting of seq data
MIPS: Fix delay slot emulation count in debugfs
MIPS: SMP: Fix possibility of deadlock when bringing CPUs online
mm: delete unnecessary and unsafe init_tlb_ubc()
huge tmpfs: fix Committed_AS leak
shmem: fix tmpfs to handle the huge= option properly
blk-mq: skip unmapped queues in blk_mq_alloc_request_hctx
MIPS: Fix pre-r6 emulation FPU initialisation
arm64: kgdb: handle read-only text / modules
arm64: Call numa_store_cpu_info() earlier.
locking/hung_task: Fix typo in CONFIG_DETECT_HUNG_TASK help text
nvme-rdma: only clear queue flags after successful connect
i2c: qup: skip qup_i2c_suspend if the device is already runtime suspended
perf/core: Limit matching exclusive events to one PMU
...
drivers/platform/x86/dell-smo8800.c is touched due to the following obscenity:
drivers/platform/x86/dell-smo8800.c ->
linux/interrupt.h ->
linux/hardirq.h ->
asm/hardirq.h ->
linux/irq.h ->
asm/hw_irq.h ->
asm/sections.h ->
asm/uaccess.h
is the only chain of includes pulling asm/uaccess.h there.
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
It was introduced in "arch, x86: pmem api for ensuring durability
of persistent memory updates" in July 2015, along with the code
that really used that stuff. Three weeks later all that code
got moved to asm/pmem.h by "pmem, x86: move x86 PMEM API to new
pmem.h header"; include, however, was left behind.
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Fix up the silent merge conflict between commit c291b01515 in x86/urgent
and commit f7c28833c2 in x86/apic which both remove num_processors++
from the original location and then add it at two different locations. As a
result num_processors is incremented twice which can cut the number of
available cpus in half.
Remove the one which is added by commit c291b01515.
In hindsight I should have merged x86/urgent into x86/apic _before_ adding
the nodeid bits, but in hindsight we are always smarter.
Reported-and-tested-by: Borislav Petkov <bp@alien8.de>
Reported-by: Mike Galbraith <umgwanakikbuti@gmail.com>
Fixes: 1e1b37273c ("Merge branch 'x86/urgent' into x86/apic")
Link: https://lkml.kernel.org/r/alpine.DEB.2.20.1609261350090.5483@nanos
Cc: Dou Liyang <douly.fnst@cn.fujitsu.com>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Bring in the upstream modifications so we can fixup the silent merge
conflict which is introduced by this merge.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Simplify exit_mce_inject() by using debugfs_remove_recursive() and do
away with the noodling over the dentry elements.
Signed-off-by: Borislav Petkov <bp@suse.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160926083152.30848-3-bp@alien8.de
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Change predecrement compare to post decrement compare to avoid an
unsigned integer wrap-around comparisomn when decrementing in the while
loop.
For example, if the debugfs_create_file() fails when 'i' is zero, the
current situation will predecrement 'i' in the while loop, wrapping 'i' to
the maximum signed integer and cause multiple out of bounds reads on
dfs_fls[i].d as the loop interates to zero.
Also, as Borislav Petkov suggested, return -ENODEV rather than -ENOMEM
on the error condition.
Signed-off-by: Colin Ian King <colin.king@canonical.com>
Signed-off-by: Borislav Petkov <bp@suse.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Yazen Ghannam <Yazen.Ghannam@amd.com>
Link: http://lkml.kernel.org/r/20160926083152.30848-2-bp@alien8.de
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Pull perf fixes from Thomas Gleixner:
"Three fixlets for perf:
- add a missing NULL pointer check in the intel BTS driver
- make BTS an exclusive PMU because BTS can only handle one event at
a time
- ensure that exclusive events are limited to one PMU so that several
exclusive events can be scheduled on different PMU instances"
* 'perf-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
perf/core: Limit matching exclusive events to one PMU
perf/x86/intel/bts: Make it an exclusive PMU
perf/x86/intel/bts: Make sure debug store is valid
In case of error, the function platform_device_register_simple()
returns ERR_PTR() and never returns NULL. The NULL test in the
return value check must therefor be replaced with IS_ERR().
Signed-off-by: Wei Yongjun <weiyongjun1@huawei.com>
Acked-by: Vadim Pasternak <vadimp@mellanox.com>
Cc: platform-driver-x86@vger.kernel.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Linus reported the following objtool warning:
kernel/signal.o: warning: objtool: .altinstr_replacement+0x54: call without frame pointer save/setup
The warning is valid. It's caused by the fact that gcc placed the call
instruction in alternative_call_2()'s inline asm before the frame
pointer setup, which breaks frame pointer convention and can result in a
bad stack trace.
Force a stack frame to be created before the call instruction by listing
the stack pointer as an output operand in the inline asm statement.
Reported-and-tested-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160923214939.j5o7c67nhepzmh3t@treble
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Add set_dev_domain_options() to set PCI domain-specific options as devices
are added. The first usage is to request exclusive userspace control of
PCIe hotplug indicators in VMD domains.
Devices in a VMD domain use PCIe hotplug Attention and Power Indicators in
a non-standard way; tell pciehp to ignore the indicators so userspace can
control them via the sysfs "attention" file.
To determine whether a bus is within a VMD domain, add a bool to the
pci_sysdata structure that the VMD driver sets during initialization.
[bhelgaas: changelog]
Requested-by: Kapil Karkra <kapil.karkra@intel.com>
Tested-by: Artur Paszkiewicz <artur.paszkiewicz@intel.com>
Signed-off-by: Keith Busch <keith.busch@intel.com>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
Run kvm-unit-tests/eventinj.flat in L1:
Sending NMI to self
After NMI to self
FAIL: NMI
This test scenario is to test whether VMM can handle NMI IDT-vectoring info correctly.
At the beginning, L2 writes LAPIC to send a self NMI, the EPT page tables on both L1
and L0 are empty so:
- The L2 accesses memory can generate EPT violation which can be intercepted by L0.
The EPT violation vmexit occurred during delivery of this NMI, and the NMI info is
recorded in vmcs02's IDT-vectoring info.
- L0 walks L1's EPT12 and L0 sees the mapping is invalid, it injects the EPT violation into L1.
The vmcs02's IDT-vectoring info is reflected to vmcs12's IDT-vectoring info since
it is a nested vmexit.
- L1 receives the EPT violation, then fixes its EPT12.
- L1 executes VMRESUME to resume L2 which generates vmexit and causes L1 exits to L0.
- L0 emulates VMRESUME which is called from L1, then return to L2.
L0 merges the requirement of vmcs12's IDT-vectoring info and injects it to L2 through
vmcs02.
- The L2 re-executes the fault instruction and cause EPT violation again.
- Since the L1's EPT12 is valid, L0 can fix its EPT02
- L0 resume L2
The EPT violation vmexit occurred during delivery of this NMI again, and the NMI info
is recorded in vmcs02's IDT-vectoring info. L0 should inject the NMI through vmentry
event injection since it is caused by EPT02's EPT violation.
However, vmx_inject_nmi() refuses to inject NMI from IDT-vectoring info if vCPU is in
guest mode, this patch fix it by permitting to inject NMI from IDT-vectoring if it is
the L0's responsibility to inject NMI from IDT-vectoring info to L2.
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Radim Krčmář <rkrcmar@redhat.com>
Cc: Jan Kiszka <jan.kiszka@siemens.com>
Cc: Bandan Das <bsd@redhat.com>
Signed-off-by: Wanpeng Li <wanpeng.li@hotmail.com>
Reviewed-by: Paolo Bonzini <pbonzini@redhat.com>
Signed-off-by: Radim Krčmář <rkrcmar@redhat.com>
I observed that kvmvapic(to optimize flexpriority=N or AMD) is used
to boost TPR access when testing kvm-unit-test/eventinj.flat tpr case
on my haswell desktop (w/ flexpriority, w/o APICv). Commit (8d14695f95
x86, apicv: add virtual x2apic support) disable virtual x2apic mode
completely if w/o APICv, and the author also told me that windows guest
can't enter into x2apic mode when he developed the APICv feature several
years ago. However, it is not truth currently, Interrupt Remapping and
vIOMMU is added to qemu and the developers from Intel test windows 8 can
work in x2apic mode w/ Interrupt Remapping enabled recently.
This patch enables TPR shadow for virtual x2apic mode to boost
windows guest in x2apic mode even if w/o APICv.
Can pass the kvm-unit-test.
Suggested-by: Radim Krčmář <rkrcmar@redhat.com>
Suggested-by: Wincy Van <fanwenyi0529@gmail.com>
Reviewed-by: Radim Krčmář <rkrcmar@redhat.com>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Radim Krčmář <rkrcmar@redhat.com>
Cc: Wincy Van <fanwenyi0529@gmail.com>
Cc: Yang Zhang <yang.zhang.wz@gmail.com>
Signed-off-by: Wanpeng Li <wanpeng.li@hotmail.com>
Signed-off-by: Radim Krčmář <rkrcmar@redhat.com>
WARNING: CPU: 1 PID: 4230 at kernel/sched/core.c:7564 __might_sleep+0x7e/0x80
do not call blocking ops when !TASK_RUNNING; state=1 set at [<ffffffff8d0de7f9>] prepare_to_swait+0x39/0xa0
CPU: 1 PID: 4230 Comm: qemu-system-x86 Not tainted 4.8.0-rc5+ #47
Call Trace:
dump_stack+0x99/0xd0
__warn+0xd1/0xf0
warn_slowpath_fmt+0x4f/0x60
? prepare_to_swait+0x39/0xa0
? prepare_to_swait+0x39/0xa0
__might_sleep+0x7e/0x80
__gfn_to_pfn_memslot+0x156/0x480 [kvm]
gfn_to_pfn+0x2a/0x30 [kvm]
gfn_to_page+0xe/0x20 [kvm]
kvm_vcpu_reload_apic_access_page+0x32/0xa0 [kvm]
nested_vmx_vmexit+0x765/0xca0 [kvm_intel]
? _raw_spin_unlock_irqrestore+0x36/0x80
vmx_check_nested_events+0x49/0x1f0 [kvm_intel]
kvm_arch_vcpu_runnable+0x2d/0xe0 [kvm]
kvm_vcpu_check_block+0x12/0x60 [kvm]
kvm_vcpu_block+0x94/0x4c0 [kvm]
kvm_arch_vcpu_ioctl_run+0x619/0x1aa0 [kvm]
? kvm_arch_vcpu_ioctl_run+0xdf1/0x1aa0 [kvm]
kvm_vcpu_ioctl+0x2d3/0x7c0 [kvm]
===============================
[ INFO: suspicious RCU usage. ]
4.8.0-rc5+ #47 Not tainted
-------------------------------
./include/linux/kvm_host.h:535 suspicious rcu_dereference_check() usage!
other info that might help us debug this:
rcu_scheduler_active = 1, debug_locks = 0
1 lock held by qemu-system-x86/4230:
#0: (&vcpu->mutex){+.+.+.}, at: [<ffffffffc062975c>] vcpu_load+0x1c/0x60 [kvm]
stack backtrace:
CPU: 1 PID: 4230 Comm: qemu-system-x86 Not tainted 4.8.0-rc5+ #47
Call Trace:
dump_stack+0x99/0xd0
lockdep_rcu_suspicious+0xe7/0x120
gfn_to_memslot+0x12a/0x140 [kvm]
gfn_to_pfn+0x12/0x30 [kvm]
gfn_to_page+0xe/0x20 [kvm]
kvm_vcpu_reload_apic_access_page+0x32/0xa0 [kvm]
nested_vmx_vmexit+0x765/0xca0 [kvm_intel]
? _raw_spin_unlock_irqrestore+0x36/0x80
vmx_check_nested_events+0x49/0x1f0 [kvm_intel]
kvm_arch_vcpu_runnable+0x2d/0xe0 [kvm]
kvm_vcpu_check_block+0x12/0x60 [kvm]
kvm_vcpu_block+0x94/0x4c0 [kvm]
kvm_arch_vcpu_ioctl_run+0x619/0x1aa0 [kvm]
? kvm_arch_vcpu_ioctl_run+0xdf1/0x1aa0 [kvm]
kvm_vcpu_ioctl+0x2d3/0x7c0 [kvm]
? __fget+0xfd/0x210
? __lock_is_held+0x54/0x70
do_vfs_ioctl+0x96/0x6a0
? __fget+0x11c/0x210
? __fget+0x5/0x210
SyS_ioctl+0x79/0x90
do_syscall_64+0x81/0x220
entry_SYSCALL64_slow_path+0x25/0x25
These can be triggered by running kvm-unit-test: ./x86-run x86/vmx.flat
The nested preemption timer is based on hrtimer which is started on L2
entry, stopped on L2 exit and evaluated via the new check_nested_events
hook. The current logic adds vCPU to a simple waitqueue (TASK_INTERRUPTIBLE)
if need to yield pCPU and w/o holding srcu read lock when accesses memslots,
both can be in nested preemption timer evaluation path which results in
the warning above.
This patch fix it by leveraging request bit to async reload APIC access
page before vmentry in order to avoid to reload directly during the nested
preemption timer evaluation, it is safe since the vmcs01 is loaded and
current is nested vmexit.
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Radim Krčmář <rkrcmar@redhat.com>
Cc: Yunhong Jiang <yunhong.jiang@intel.com>
Signed-off-by: Wanpeng Li <wanpeng.li@hotmail.com>
Signed-off-by: Radim Krčmář <rkrcmar@redhat.com>
kvm_guest.config is useful for KVM guests on other arches, and nothing
in it appears to be x86 specific, so just move the whole file. Kbuild
will find it in either location.
Signed-off-by: Rob Herring <robh@kernel.org>
Cc: Christoffer Dall <christoffer.dall@linaro.org>
Cc: Marc Zyngier <marc.zyngier@arm.com>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: "Radim Krčmář" <rkrcmar@redhat.com>
Cc: kvmarm@lists.cs.columbia.edu
Cc: kvm@vger.kernel.org
Acked-by: Christoffer Dall <christoffer.dall@linaro.org>
Signed-off-by: Radim Krčmář <rkrcmar@redhat.com>
Just like intel_pt, intel_bts can only handle one event at a time,
which is the reason we introduced PERF_PMU_CAP_EXCLUSIVE in the first
place. However, at the moment one can have as many intel_bts events
within the same context at the same time as one pleases. Only one of
them, however, will get scheduled and receive the actual trace data.
Fix this by making intel_bts an "exclusive" PMU.
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Acked-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160920154811.3255-2-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
In commit:
ec776ef6bb ("x86/mm: Add support for the non-standard protected e820 type")
Christoph references the original patch I wrote implementing pmem support.
The intent of the 'max_pfn' changes in that commit were to enable persistent
memory ranges to be covered by the struct page memmap by default.
However, that approach was abandoned when Christoph ported the patches [1], and
that functionality has since been replaced by devm_memremap_pages().
In the meantime, this max_pfn manipulation is confusing kdump [2] that
assumes that everything covered by the max_pfn is "System RAM". This
results in kdump hanging or crashing.
[1]: https://lists.01.org/pipermail/linux-nvdimm/2015-March/000348.html
[2]: https://bugzilla.redhat.com/show_bug.cgi?id=1351098
So fix it.
Reported-by: Zhang Yi <yizhan@redhat.com>
Reported-by: Jeff Moyer <jmoyer@redhat.com>
Tested-by: Zhang Yi <yizhan@redhat.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Reviewed-by: Jeff Moyer <jmoyer@redhat.com>
Cc: <stable@vger.kernel.org> # v4.1 and later kernels
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Boaz Harrosh <boaz@plexistor.com>
Cc: Christoph Hellwig <hch@lst.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Ross Zwisler <ross.zwisler@linux.intel.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-nvdimm@lists.01.org
Fixes: ec776ef6bb ("x86/mm: Add support for the non-standard protected e820 type")
Link: http://lkml.kernel.org/r/147448744538.34910.11287693517367139607.stgit@dwillia2-desk3.amr.corp.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Add the UV4-specific function definitions and define an operations struct
to implement them in the BAU driver.
Many BAU MMRs, although functionally the same, have new addresses on UV4
due to hardware changes. Each MMR requires new read/write functions, but
their implementation in the driver does not change. Thus, it is enough to
enumerate them in the operations struct for the changes to take effect.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-11-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The BAU on UV4 does not need to maintain the payload queue tail pointer. Do
not initialize the tail pointer MMR on UV4.
Note that write_payload_tail is not an abstracted BAU function since it is
an operation specific to pre-UV4 versions. Then we must switch on the UV
version to control its usage, for which we use uvhub_version rather than
is_uv*_hub because it is quicker/more concise.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-10-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Software timeouts are not currently supported on BAU for UV4. Instead, the
BAU will rely on hardware-level fairness protocols to determine broadcast
timeouts.
Do not call enable_timeouts or calculate_destination_timeout on UV4. These
functions write to pre-UV4 MMRs so they generate error messages on UV4.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-9-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Convert the use of UV version-specific functions to their abstracted
counterparts.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-7-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Many BAU functions have different implementations depending on the UV
version. Rather than switching on the uvhub_version throughout the driver,
we can define a set of operations for each version. This is especially
beneficial for UV4, which will require many new MMR read/write functions.
Currently, the set of abstracted functions are the same for UV1, UV2, and
UV3. The functions were chosen because each one will have a different
implementation for UV4. Other functions will be added as needed to handle
new implementations or to cleanup the existing differences between UV1,
UV2, and UV3, i.e. read_status and wait_completion.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-6-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The BAU driver should use the functions provided by uv_hub.h rather than
its own implementations. uv_physnodeaddr converts vaddrs to paddrs for
BAU MMR fields, but this is done better by uv_gpa_to_offset.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-5-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The payload queue first MMR requires the physical memory address and hub
GNODE of where the payload queue resides in memory, but the associated
variables are named as if the PNODE were used. Rename gnode-related
variables and clarify the definitions of the payload queue head, last, and
tail pointers.
Signed-off-by: Andrew Banman <abanman@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Acked-by: Mike Travis <travis@sgi.com>
Acked-by: Dimitri Sivanich <sivanich@sgi.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: akpm@linux-foundation.org
Cc: rja@sgi.com
Link: http://lkml.kernel.org/r/1474474161-265604-4-git-send-email-abanman@sgi.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The whole patch-set aims at making cpuid <-> nodeid mapping persistent. So that,
when node online/offline happens, cache based on cpuid <-> nodeid mapping such as
wq_numa_possible_cpumask will not cause any problem.
It contains 4 steps:
1. Enable apic registeration flow to handle both enabled and disabled cpus.
2. Introduce a new array storing all possible cpuid <-> apicid mapping.
3. Enable _MAT and MADT relative apis to return non-present or disabled cpus' apicid.
4. Establish all possible cpuid <-> nodeid mapping.
This patch finishes step 2.
In this patch, we introduce a new static array named cpuid_to_apicid[],
which is large enough to store info for all possible cpus.
And then, we modify the cpuid calculation. In generic_processor_info(),
it simply finds the next unused cpuid. And it is also why the cpuid <-> nodeid
mapping changes with node hotplug.
After this patch, we find the next unused cpuid, map it to an apicid,
and store the mapping in cpuid_to_apicid[], so that cpuid <-> apicid
mapping will be persistent.
And finally we will use this array to make cpuid <-> nodeid persistent.
cpuid <-> apicid mapping is established at local apic registeration time.
But non-present or disabled cpus are ignored.
In this patch, we establish all possible cpuid <-> apicid mapping when
registering local apic.
Signed-off-by: Gu Zheng <guz.fnst@cn.fujitsu.com>
Signed-off-by: Tang Chen <tangchen@cn.fujitsu.com>
Signed-off-by: Zhu Guihua <zhugh.fnst@cn.fujitsu.com>
Signed-off-by: Dou Liyang <douly.fnst@cn.fujitsu.com>
Acked-by: Ingo Molnar <mingo@kernel.org>
Cc: mika.j.penttila@gmail.com
Cc: len.brown@intel.com
Cc: rafael@kernel.org
Cc: rjw@rjwysocki.net
Cc: yasu.isimatu@gmail.com
Cc: linux-mm@kvack.org
Cc: linux-acpi@vger.kernel.org
Cc: isimatu.yasuaki@jp.fujitsu.com
Cc: gongzhaogang@inspur.com
Cc: tj@kernel.org
Cc: izumi.taku@jp.fujitsu.com
Cc: cl@linux.com
Cc: chen.tang@easystack.cn
Cc: akpm@linux-foundation.org
Cc: kamezawa.hiroyu@jp.fujitsu.com
Cc: lenb@kernel.org
Link: http://lkml.kernel.org/r/1472114120-3281-4-git-send-email-douly.fnst@cn.fujitsu.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
cpuid <-> nodeid mapping is firstly established at boot time. And workqueue caches
the mapping in wq_numa_possible_cpumask in wq_numa_init() at boot time.
When doing node online/offline, cpuid <-> nodeid mapping is established/destroyed,
which means, cpuid <-> nodeid mapping will change if node hotplug happens. But
workqueue does not update wq_numa_possible_cpumask.
So here is the problem:
Assume we have the following cpuid <-> nodeid in the beginning:
Node | CPU
------------------------
node 0 | 0-14, 60-74
node 1 | 15-29, 75-89
node 2 | 30-44, 90-104
node 3 | 45-59, 105-119
and we hot-remove node2 and node3, it becomes:
Node | CPU
------------------------
node 0 | 0-14, 60-74
node 1 | 15-29, 75-89
and we hot-add node4 and node5, it becomes:
Node | CPU
------------------------
node 0 | 0-14, 60-74
node 1 | 15-29, 75-89
node 4 | 30-59
node 5 | 90-119
But in wq_numa_possible_cpumask, cpu30 is still mapped to node2, and the like.
When a pool workqueue is initialized, if its cpumask belongs to a node, its
pool->node will be mapped to that node. And memory used by this workqueue will
also be allocated on that node.
static struct worker_pool *get_unbound_pool(const struct workqueue_attrs *attrs){
...
/* if cpumask is contained inside a NUMA node, we belong to that node */
if (wq_numa_enabled) {
for_each_node(node) {
if (cpumask_subset(pool->attrs->cpumask,
wq_numa_possible_cpumask[node])) {
pool->node = node;
break;
}
}
}
Since wq_numa_possible_cpumask is not updated, it could be mapped to an offline node,
which will lead to memory allocation failure:
SLUB: Unable to allocate memory on node 2 (gfp=0x80d0)
cache: kmalloc-192, object size: 192, buffer size: 192, default order: 1, min order: 0
node 0: slabs: 6172, objs: 259224, free: 245741
node 1: slabs: 3261, objs: 136962, free: 127656
It happens here:
create_worker(struct worker_pool *pool)
|--> worker = alloc_worker(pool->node);
static struct worker *alloc_worker(int node)
{
struct worker *worker;
worker = kzalloc_node(sizeof(*worker), GFP_KERNEL, node); --> Here, useing the wrong node.
......
return worker;
}
[Solution]
There are four mappings in the kernel:
1. nodeid (logical node id) <-> pxm
2. apicid (physical cpu id) <-> nodeid
3. cpuid (logical cpu id) <-> apicid
4. cpuid (logical cpu id) <-> nodeid
1. pxm (proximity domain) is provided by ACPI firmware in SRAT, and nodeid <-> pxm
mapping is setup at boot time. This mapping is persistent, won't change.
2. apicid <-> nodeid mapping is setup using info in 1. The mapping is setup at boot
time and CPU hotadd time, and cleared at CPU hotremove time. This mapping is also
persistent.
3. cpuid <-> apicid mapping is setup at boot time and CPU hotadd time. cpuid is
allocated, lower ids first, and released at CPU hotremove time, reused for other
hotadded CPUs. So this mapping is not persistent.
4. cpuid <-> nodeid mapping is also setup at boot time and CPU hotadd time, and
cleared at CPU hotremove time. As a result of 3, this mapping is not persistent.
To fix this problem, we establish cpuid <-> nodeid mapping for all the possible
cpus at boot time, and make it persistent. And according to init_cpu_to_node(),
cpuid <-> nodeid mapping is based on apicid <-> nodeid mapping and cpuid <-> apicid
mapping. So the key point is obtaining all cpus' apicid.
apicid can be obtained by _MAT (Multiple APIC Table Entry) method or found in
MADT (Multiple APIC Description Table). So we finish the job in the following steps:
1. Enable apic registeration flow to handle both enabled and disabled cpus.
This is done by introducing an extra parameter to generic_processor_info to let the
caller control if disabled cpus are ignored.
2. Introduce a new array storing all possible cpuid <-> apicid mapping. And also modify
the way cpuid is calculated. Establish all possible cpuid <-> apicid mapping when
registering local apic. Store the mapping in this array.
3. Enable _MAT and MADT relative apis to return non-present or disabled cpus' apicid.
This is also done by introducing an extra parameter to these apis to let the caller
control if disabled cpus are ignored.
4. Establish all possible cpuid <-> nodeid mapping.
This is done via an additional acpi namespace walk for processors.
This patch finished step 1.
Signed-off-by: Gu Zheng <guz.fnst@cn.fujitsu.com>
Signed-off-by: Tang Chen <tangchen@cn.fujitsu.com>
Signed-off-by: Zhu Guihua <zhugh.fnst@cn.fujitsu.com>
Signed-off-by: Dou Liyang <douly.fnst@cn.fujitsu.com>
Acked-by: Ingo Molnar <mingo@kernel.org>
Cc: mika.j.penttila@gmail.com
Cc: len.brown@intel.com
Cc: rafael@kernel.org
Cc: rjw@rjwysocki.net
Cc: yasu.isimatu@gmail.com
Cc: linux-mm@kvack.org
Cc: linux-acpi@vger.kernel.org
Cc: isimatu.yasuaki@jp.fujitsu.com
Cc: gongzhaogang@inspur.com
Cc: tj@kernel.org
Cc: izumi.taku@jp.fujitsu.com
Cc: cl@linux.com
Cc: chen.tang@easystack.cn
Cc: akpm@linux-foundation.org
Cc: kamezawa.hiroyu@jp.fujitsu.com
Cc: lenb@kernel.org
Link: http://lkml.kernel.org/r/1472114120-3281-3-git-send-email-douly.fnst@cn.fujitsu.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
For now, x86 does not support memory-less node. A node without memory
will not be onlined, and the cpus on it will be mapped to the other
online nodes with memory in init_cpu_to_node(). The reason of doing this
is to ensure each cpu has mapped to a node with memory, so that it will
be able to allocate local memory for that cpu.
But we don't have to do it in this way.
In this series of patches, we are going to construct cpu <-> node mapping
for all possible cpus at boot time, which is a persistent mapping. It means
that the cpu will be mapped to the node which it belongs to, and will never
be changed. If a node has only cpus but no memory, the cpus on it will be
mapped to a memory-less node. And the memory-less node should be onlined.
Allocate pgdats for all memory-less nodes and online them at boot
time. Then build zonelists for these nodes. As a result, when cpus on these
memory-less nodes try to allocate memory from local node, it will
automatically fall back to the proper zones in the zonelists.
Signed-off-by: Zhu Guihua <zhugh.fnst@cn.fujitsu.com>
Signed-off-by: Dou Liyang <douly.fnst@cn.fujitsu.com>
Acked-by: Ingo Molnar <mingo@kernel.org>
Cc: mika.j.penttila@gmail.com
Cc: len.brown@intel.com
Cc: Tang Chen <tangchen@cn.fujitsu.com>
Cc: rafael@kernel.org
Cc: rjw@rjwysocki.net
Cc: yasu.isimatu@gmail.com
Cc: linux-mm@kvack.org
Cc: linux-acpi@vger.kernel.org
Cc: isimatu.yasuaki@jp.fujitsu.com
Cc: gongzhaogang@inspur.com
Cc: tj@kernel.org
Cc: izumi.taku@jp.fujitsu.com
Cc: cl@linux.com
Cc: chen.tang@easystack.cn
Cc: akpm@linux-foundation.org
Cc: kamezawa.hiroyu@jp.fujitsu.com
Cc: lenb@kernel.org
Link: http://lkml.kernel.org/r/1472114120-3281-2-git-send-email-douly.fnst@cn.fujitsu.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Optimize RAID6 gen_syndrom functions to take advantage of
the 512-bit ZMM integer instructions introduced in AVX512.
AVX512 optimized gen_syndrom functions, which is simply based
on avx2.c written by Yuanhan Liu and sse2.c written by hpa.
The patch was tested and benchmarked before submission on
a hardware that has AVX512 flags to support such instructions
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Jim Kukunas <james.t.kukunas@linux.intel.com>
Cc: Fenghua Yu <fenghua.yu@intel.com>
Signed-off-by: Megha Dey <megha.dey@linux.intel.com>
Signed-off-by: Gayatri Kammela <gayatri.kammela@intel.com>
Reviewed-by: Fenghua Yu <fenghua.yu@intel.com>
Signed-off-by: Shaohua Li <shli@fb.com>
The maximum size of e820 map array for EFI systems is defined as
E820_X_MAX (E820MAX + 3 * MAX_NUMNODES).
In x86_64 defconfig, this ends up with E820_X_MAX = 320, e820 and e820_saved
are 6404 bytes each.
With larger configs, for example Fedora kernels, E820_X_MAX = 3200, e820
and e820_saved are 64004 bytes each. Most of this space is wasted.
Typical machines have some 20-30 e820 areas at most.
After previous patch, e820 and e820_saved are pointers to e280 maps.
Change them to initially point to maps which are __initdata.
At the very end of kernel init, just before __init[data] sections are freed
in free_initmem(), allocate smaller blocks, copy maps there,
and change pointers.
The late switch makes sure that all functions which can be used to change
e820 maps are no longer accessible (they are all __init functions).
Run-tested.
Signed-off-by: Denys Vlasenko <dvlasenk@redhat.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Andy Lutomirski <luto@amacapital.net>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Yinghai Lu <yinghai@kernel.org>
Cc: linux-kernel@vger.kernel.org
Link: http://lkml.kernel.org/r/20160918182125.21000-1-dvlasenk@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
This patch turns e820 and e820_saved into pointers to e820 tables,
of the same size as before.
Signed-off-by: Denys Vlasenko <dvlasenk@redhat.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Andy Lutomirski <luto@amacapital.net>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Yinghai Lu <yinghai@kernel.org>
Cc: linux-kernel@vger.kernel.org
Link: http://lkml.kernel.org/r/20160917213927.1787-2-dvlasenk@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
They are all called only from other __init functions in e820.c
Signed-off-by: Denys Vlasenko <dvlasenk@redhat.com>
Acked-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Andy Lutomirski <luto@amacapital.net>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Yinghai Lu <yinghai@kernel.org>
Cc: linux-kernel@vger.kernel.org
Link: http://lkml.kernel.org/r/20160917213927.1787-1-dvlasenk@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
With the following commit:
e18bcccd1a ("x86/dumpstack: Convert show_trace_log_lvl() to use the new unwinder")
The task pointer argument to show_stack_log_lvl() in show_stack() was
inadvertently changed to 'current'.
Signed-off-by: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: byungchul.park@lge.com
Cc: fweisbec@gmail.com
Cc: keescook@chromium.org
Cc: linux-tip-commits@vger.kernel.org
Cc: luto@amacapital.net
Cc: nilayvaish@gmail.com
Cc: rostedt@goodmis.org
Cc: tip-bot for Josh Poimboeuf <tipbot@zytor.com>
Fixes: e18bcccd1a ("x86/dumpstack: Convert show_trace_log_lvl() to use the new unwinder")
Link: http://lkml.kernel.org/r/20160920155340.yhewlx7vmgmov5fb@treble
Signed-off-by: Ingo Molnar <mingo@kernel.org>
new EFI memory map reservation code didn't align reservations to
EFI_PAGE_SIZE boundaries causing bogus regions to be inserted into
the global EFI memory map - Matt Fleming
-----BEGIN PGP SIGNATURE-----
iQI2BAABCAAgBQJX4UshGRxtYXR0QGNvZGVibHVlcHJpbnQuY28udWsACgkQLzhZ
wI0jPVX2RA/9HiT48K98R1fkiig/V3Wh8H8y7lQbwO+qA1WZ7q/D+DYau62qI3zM
sLgTSoV2zzjBr+4JWuGIdbtpYBjhHci0HwEcOGp5EFSZmgJGOpc7VY2VdFaYyZ2X
xhowGLXv2jgfKoAPt9MfgZX2Qh5Jt4CRlC+UcilUJp0wy1+uD4W7XmrLM1Rg7Ug2
8XTL/BA5QxQa3wx8+/z6xV/ADlhzf3DQ7BwI3qkx5RHSXSuy1/E2XGTnyuDt/7Oo
KmMwQGGrrv92uSjyq5vJ53DuNxXDJ7nGtlXTT2u0WtcZbzJXsXIaCZItbCA5rqW/
wWGgsz5XSc406m1WNv8Zs8xx9NAEP/+KXQfftwuQHFqoylG4QqYuO060V5XOxQlh
cdRuyVUgMONZAvTzEAUC+5SaN3c+WDCL8oEnrs/tdMxSzBL9Rj7yaHMW+ozVe5Nf
GFxMnO0l5SG9+o8hSAkkn5RDfIDzSTC1W5imqWJQXhC2BXHEdmh4wVWIG4QgPM/K
gqaTpX72Nu04lBjCXXpfKSK5Xqv67hZOzxUDkkjxtq1PtDbL1dPpzAF3s3GFdreI
FfQgetg4jM4EPnWDQWqWVJxQUv+uCfpDV9g5y9kMinVb2OpyGjcZpNckGHKnqIXr
hyntPYqyy793W6dPGEjTqfcVP751qisMjp6iIIqk3h+qr7HyJSF5nqs=
=S9gJ
-----END PGP SIGNATURE-----
Merge tag 'efi-next' of git://git.kernel.org/pub/scm/linux/kernel/git/mfleming/efi into efi/core
Pull EFI fix from Matt Fleming:
* Fix a boot crash reported by Mike Galbraith and Mike Krinkin. The
new EFI memory map reservation code didn't align reservations to
EFI_PAGE_SIZE boundaries causing bogus regions to be inserted into
the global EFI memory map (Matt Fleming)
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Mike Galbraith reported that his machine started rebooting during boot
after,
commit 8e80632fb2 ("efi/esrt: Use efi_mem_reserve() and avoid a kmalloc()")
The ESRT table on his machine is 56 bytes and at no point in the
efi_arch_mem_reserve() call path is that size rounded up to
EFI_PAGE_SIZE, nor is the start address on an EFI_PAGE_SIZE boundary.
Since the EFI memory map only deals with whole pages, inserting an EFI
memory region with 56 bytes results in a new entry covering zero
pages, and completely screws up the calculations for the old regions
that were trimmed.
Round all sizes upwards, and start addresses downwards, to the nearest
EFI_PAGE_SIZE boundary.
Additionally, efi_memmap_insert() expects the mem::range::end value to
be one less than the end address for the region.
Reported-by: Mike Galbraith <umgwanakikbuti@gmail.com>
Reported-by: Mike Krinkin <krinkin.m.u@gmail.com>
Tested-by: Mike Krinkin <krinkin.m.u@gmail.com>
Cc: Peter Jones <pjones@redhat.com>
Cc: Ard Biesheuvel <ard.biesheuvel@linaro.org>
Cc: Mark Rutland <mark.rutland@arm.com>
Cc: Taku Izumi <izumi.taku@jp.fujitsu.com>
Signed-off-by: Matt Fleming <matt@codeblueprint.co.uk>
Since commit 4d4c474124 ("perf/x86/intel/bts: Fix BTS PMI detection")
my box goes boom on boot:
| .... node #0, CPUs: #1#2#3#4#5#6#7
| BUG: unable to handle kernel NULL pointer dereference at 0000000000000018
| IP: [<ffffffff8100c463>] intel_bts_interrupt+0x43/0x130
| Call Trace:
| <NMI> d [<ffffffff8100b341>] intel_pmu_handle_irq+0x51/0x4b0
| [<ffffffff81004d47>] perf_event_nmi_handler+0x27/0x40
This happens because the code introduced in this commit dereferences the
debug store pointer unconditionally. The debug store is not guaranteed to
be available, so a NULL pointer check as on other places is required.
Fixes: 4d4c474124 ("perf/x86/intel/bts: Fix BTS PMI detection")
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Reviewed-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: vince@deater.net
Cc: eranian@google.com
Link: http://lkml.kernel.org/r/20160920131220.xg5pbdjtznszuyzb@breakpoint.cc
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Waiman reported that booting with CONFIG_EFI_MIXED enabled on his
multi-terabyte HP machine results in boot crashes, because the EFI
region mapping functions loop forever while trying to map those
regions describing RAM.
While this patch doesn't fix the underlying hang, there's really no
reason to map EFI_CONVENTIONAL_MEMORY regions into the EFI page tables
when mixed-mode is not in use at runtime.
Reported-by: Waiman Long <waiman.long@hpe.com>
Cc: Ard Biesheuvel <ard.biesheuvel@linaro.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
CC: Theodore Ts'o <tytso@mit.edu>
Cc: Arnd Bergmann <arnd@arndb.de>
Cc: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Cc: Scott J Norton <scott.norton@hpe.com>
Cc: Douglas Hatch <doug.hatch@hpe.com>
Cc: <stable@vger.kernel.org> # v4.6+
Signed-off-by: Matt Fleming <matt@codeblueprint.co.uk>
There's a mixture of signed 32-bit and unsigned 32-bit and 64-bit data
types used for keeping track of how many pages have been mapped.
This leads to hangs during boot when mapping large numbers of pages
(multiple terabytes, as reported by Waiman) because those values are
interpreted as being negative.
commit 742563777e ("x86/mm/pat: Avoid truncation when converting
cpa->numpages to address") fixed one of those bugs, but there is
another lurking in __change_page_attr_set_clr().
Additionally, the return value type for the populate_*() functions can
return negative values when a large number of pages have been mapped,
triggering the error paths even though no error occurred.
Consistently use 64-bit types on 64-bit platforms when counting pages.
Even in the signed case this gives us room for regions 8PiB
(pebibytes) in size whilst still allowing the usual negative value
error checking idiom.
Reported-by: Waiman Long <waiman.long@hpe.com>
Cc: Ard Biesheuvel <ard.biesheuvel@linaro.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
CC: Theodore Ts'o <tytso@mit.edu>
Cc: Arnd Bergmann <arnd@arndb.de>
Cc: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Cc: Scott J Norton <scott.norton@hpe.com>
Cc: Douglas Hatch <doug.hatch@hpe.com>
Signed-off-by: Matt Fleming <matt@codeblueprint.co.uk>
vm_data->avic_vm_id is a u32, so the check for a error
return (less than zero) such as -EAGAIN from
avic_get_next_vm_id currently has no effect whatsoever.
Fix this by using a temporary int for the comparison
and assign vm_data->avic_vm_id to this. I used an explicit
u32 cast in the assignment to show why vm_data->avic_vm_id
cannot be used in the assign/compare steps.
Signed-off-by: Colin Ian King <colin.king@canonical.com>
Acked-by: Joerg Roedel <jroedel@suse.de>
Signed-off-by: Paolo Bonzini <pbonzini@redhat.com>
Lately tsc page was implemented but filled with empty
values. This patch setup tsc page scale and offset based
on vcpu tsc, tsc_khz and HV_X64_MSR_TIME_REF_COUNT value.
The valid tsc page drops HV_X64_MSR_TIME_REF_COUNT msr
reads count to zero which potentially improves performance.
Signed-off-by: Andrey Smetanin <asmetanin@virtuozzo.com>
Reviewed-by: Peter Hornyack <peterhornyack@google.com>
Reviewed-by: Radim Krčmář <rkrcmar@redhat.com>
CC: Paolo Bonzini <pbonzini@redhat.com>
CC: Roman Kagan <rkagan@virtuozzo.com>
CC: Denis V. Lunev <den@openvz.org>
[Computation of TSC page parameters rewritten to use the Linux timekeeper
parameters. - Paolo]
Signed-off-by: Paolo Bonzini <pbonzini@redhat.com>
Introduce a function that reads the exact nanoseconds value that is
provided to the guest in kvmclock. This crystallizes the notion of
kvmclock as a thin veneer over a stable TSC, that the guest will
(hopefully) convert with NTP. In other words, kvmclock is *not* a
paravirtualized host-to-guest NTP.
Drop the get_kernel_ns() function, that was used both to get the base
value of the master clock and to get the current value of kvmclock.
The former use is replaced by ktime_get_boot_ns(), the latter is
the purpose of get_kernel_ns().
This also allows KVM to provide a Hyper-V time reference counter that
is synchronized with the time that is computed from the TSC page.
Reviewed-by: Roman Kagan <rkagan@virtuozzo.com>
Signed-off-by: Paolo Bonzini <pbonzini@redhat.com>
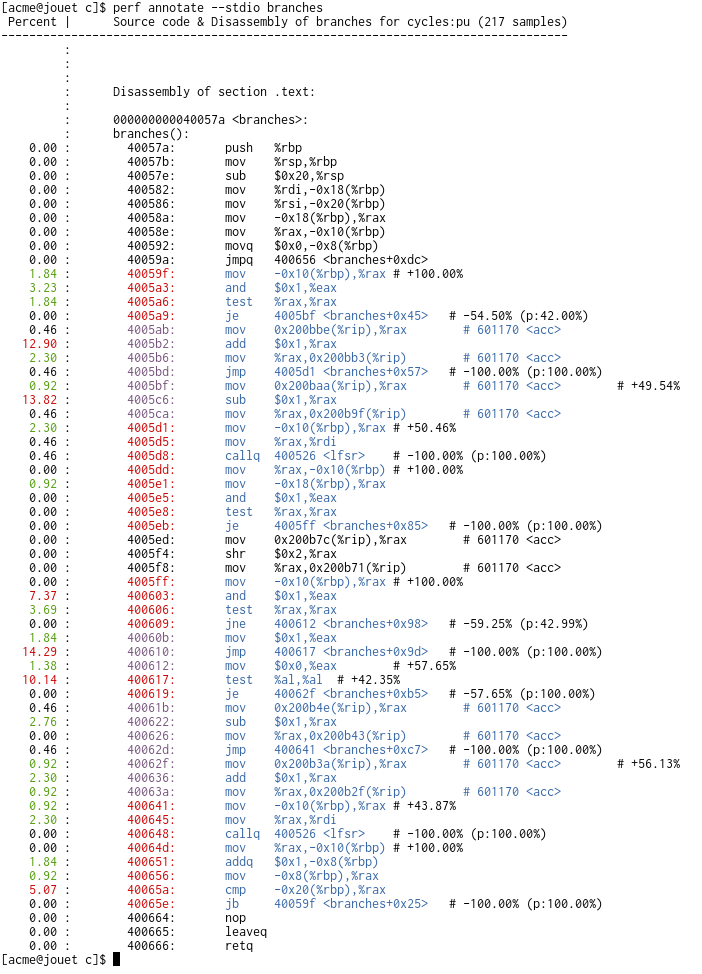{kind=link}