This change is meant to improve performance on systems that do not require
the DMA unmap calls. On those systems we do not need to make use of the
unmap address for Tx or the unmap length so we can drop both thereby
reducing the size of the Tx buffer info structure.
In addition I have changed the logic to check for unmap length instead of
unmap address when checking to see if a buffer needs to be unmapped from
DMA use. The reasons for this change is that on some platforms it is
possible to receive a valid DMA address of 0 from an IOMMU.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Instead of storing the RSS key as a character array we can simplify the
configuration by making it a u32 array. This allows us to just write one
value per register without any unnecessary operations to construct the
value.
This change will produce the same exact key, the only difference is that I
translated the u8 array to a u32 array which will be correctly ordered on
writes to hardware by the cpu_to_le32 operations that are built into the
writel calls.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
This patch cleans up our RSS indirection table configuration so that we
generate the same table regardless of CPU endianness. In addition it
changes the table setup so that instead of doing a modulo based setup it is
instead a divisor based setup. The advantage to this is that we should be
able to take the Rx hash and compute the Rx queue with very little CPU
overhead if needed.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
This change makes it so that Tx cleanup is done in a do/while loop instead
of a for loop. The main motivation behind this is the fact that we should
never be invoked with a budget less than 1 so we can skip checking the
budget before processing the first descriptor.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
This change removes the code that was doing the NUMA allocations for the
q_vectors, rings, and ring resources. The problem is the logic used assumed
that the NUMA nodes were always interleved and that is not always the case.
At some point I hope to add this functionality back in a more controlled
manner in the future.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Due to a hardware issue, on i210 and i211 parts, the TNCRS statistic
provides an invalid value. This patch changes the update stats function
to increment the stat only for non-i210/i211 parts.
Signed-off-by: Carolyn Wyborny <carolyn.wyborny@intel.com>
Tested-by: Jeff Pieper <jeffrey.e.pieper@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Adapt the pre-existing and assigned VFs code to the ixgbe way introduced
in commit 9297127b9c.
Instead of searching the enabled VFs we use pci_num_vf to determine enabled VFs.
By comparing to which PF an assigned VF is owned it's possible to decide
whether to leave it enabled or not.
Signed-off-by: Stefan Assmann <sassmann@kpanic.de>
Acked-by: Greg Rose <gregory.v.rose@intel.com>
Tested-by: Robert Garrett <robertx.e.garrett@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
In case of error, the function clk_get() returns ERR_PTR()
and never returns NULL pointer. The NULL test in the error
handling should be replaced with IS_ERR().
dpatch engine is used to auto generated this patch.
(https://github.com/weiyj/dpatch)
Cc: stable <stable@vger.kernel.org>
Signed-off-by: Wei Yongjun <yongjun_wei@trendmicro.com.cn>
Acked-by: Wolfgang Grandegger <wg@grandegger.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Rename generic-sounding function dump_mem() to pcan_dump_mem()
so that it does not conflict with the dump_mem() function in
arch/sh/include/asm/kdebug.h.
drivers/net/can/usb/peak_usb/pcan_usb_core.c: error: conflicting types for 'dump_mem': => 56:6
drivers/net/can/usb/peak_usb/pcan_usb_core.h: error: conflicting types for 'dump_mem': => 134:6
Signed-off-by: Randy Dunlap <rdunlap@xenotime.net>
Reported-by: Geert Uytterhoeven <geert@linux-m68k.org>
Cc: Stephane Grosjean <s.grosjean@peak-system.com>
Cc: Wolfgang Grandegger <wg@grandegger.com>
Cc: Marc Kleine-Budde <mkl@pengutronix.de>
[mkl: convert all users of dump_mem(), too]
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Adopt pinctrl support to c_can driver based on c_can device
pointer, pinctrl driver configure SoC pins to d_can mode
according to definitions provided in .dts file.
In device specific device tree file 'pinctrl-names = "default";'
and 'pinctrl-0 = <&d_can1_pins>;' needs to add to configure pins
from c_can driver. d_can1_pins node contains the pinmux/config
details of d_can L/H pins.
Signed-off-by: AnilKumar Ch <anilkumar@ti.com>
Acked-by: Tony Lindgren <tony@atomide.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Adds suspend resume support to DCAN driver which enables
DCAN power down mode bit (PDR). Then DCAN will ack the local
power-down mode by setting PDA bit in STATUS register.
Signed-off-by: AnilKumar Ch <anilkumar@ti.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Add Runtime PM support to C_CAN/D_CAN controller. The runtime PM
APIs control clocks for C_CAN/D_CAN IP and prevent access to the
register of C_CAN/D_CAN IP when clock is turned off.
Signed-off-by: AnilKumar Ch <anilkumar@ti.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Add device tree support to C_CAN/D_CAN controller and usage details
are added to device tree documentation. Driver was tested on AM335x
EVM.
Signed-off-by: AnilKumar Ch <anilkumar@ti.com>
For the of binding doc:
Reviewed-by: Stephen Warren <swarren@nvidia.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Modify c_can device names from *_CAN_DEVTYPE to BOSCH_*_CAN to make
use of same names for array indexes in c_can_id_table[] as well as
device names.
This patch also add indexes to c_can_id_table array.
Signed-off-by: AnilKumar Ch <anilkumar@ti.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
bitmap:ip and bitmap:ip,mac type did not reject such a crazy range
when created and using such a set results in a kernel crash.
The hash types just silently ignored such parameters.
Reject invalid /0 input parameters explicitely.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Since (9f00d97 netlink: hide struct module parameter in netlink_kernel_create),
linux/netlink.h includes linux/module.h because of the use of THIS_MODULE.
Use linux/export.h instead, as suggested by Stephen Rothwell, which is
significantly smaller and defines THIS_MODULES.
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Commit eb716c54b1 ("sunbmac: remove
unnecessary setting of skb->dev") caused the local varible 'dev'
in bigmac_init_rings to become unused. And now the compiler
warns about it.
Signed-off-by: David S. Miller <davem@davemloft.net>
On some hw, link is not up during adding iface to team. That causes event
not being sent to userspace and that may cause confusion.
Fix this bug by sending port changed event once it's added to team.
Signed-off-by: Jiri Pirko <jiri@resnulli.us>
Signed-off-by: David S. Miller <davem@davemloft.net>
On small systems (e.g. embedded ones) IP addresses are often configured
by bootloaders and get assigned to kernel via parameter "ip=". If set to
"ip=dhcp", even nameserver entries from DHCP daemons are handled. These
entries exported in /proc/net/pnp are commonly linked by /etc/resolv.conf.
To configure nameservers for networks without DHCP, this patch adds option
<dns0-ip> and <dns1-ip> to kernel-parameter 'ip='.
Signed-off-by: Christoph Fritz <chf.fritz@googlemail.com>
Tested-by: Jan Weitzel <j.weitzel@phytec.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
One of the modes of Huawei E367 has this QMI/wwan interface:
I:* If#= 1 Alt= 0 #EPs= 3 Cls=ff(vend.) Sub=01 Prot=07 Driver=(none)
E: Ad=83(I) Atr=03(Int.) MxPS= 64 Ivl=2ms
E: Ad=84(I) Atr=02(Bulk) MxPS= 512 Ivl=0ms
E: Ad=02(O) Atr=02(Bulk) MxPS= 512 Ivl=4ms
Huawei use subclass and protocol to identify vendor specific
functions, so adding a new vendor rule for this combination.
The Pantech devices UML290 (106c:3718) and P4200 (106c:3721) use
the same subclass to identify the QMI/wwan function. Replace the
existing device specific UML290 entries with generic vendor matching,
adding support for the Pantech P4200.
The ZTE MF683 has 6 vendor specific interfaces, all using
ff/ff/ff for cls/sub/prot. Adding a match on interface #5 which
is a QMI/wwan interface.
Cc: Fangxiaozhi (Franko) <fangxiaozhi@huawei.com>
Cc: Thomas Schäfer <tschaefer@t-online.de>
Cc: Dan Williams <dcbw@redhat.com>
Cc: Shawn J. Goff <shawn7400@gmail.com>
Signed-off-by: Bjørn Mork <bjorn@mork.no>
Signed-off-by: David S. Miller <davem@davemloft.net>
When CONFIG_IPV6=m and CONFIG_L2TP=y, I got the following compile error:
LD init/built-in.o
net/built-in.o: In function `l2tp_xmit_core':
l2tp_core.c:(.text+0x147781): undefined reference to `inet6_csk_xmit'
net/built-in.o: In function `l2tp_tunnel_create':
(.text+0x149067): undefined reference to `udpv6_encap_enable'
net/built-in.o: In function `l2tp_ip6_recvmsg':
l2tp_ip6.c:(.text+0x14e991): undefined reference to `ipv6_recv_error'
net/built-in.o: In function `l2tp_ip6_sendmsg':
l2tp_ip6.c:(.text+0x14ec64): undefined reference to `fl6_sock_lookup'
l2tp_ip6.c:(.text+0x14ed6b): undefined reference to `datagram_send_ctl'
l2tp_ip6.c:(.text+0x14eda0): undefined reference to `fl6_sock_lookup'
l2tp_ip6.c:(.text+0x14ede5): undefined reference to `fl6_merge_options'
l2tp_ip6.c:(.text+0x14edf4): undefined reference to `ipv6_fixup_options'
l2tp_ip6.c:(.text+0x14ee5d): undefined reference to `fl6_update_dst'
l2tp_ip6.c:(.text+0x14eea3): undefined reference to `ip6_dst_lookup_flow'
l2tp_ip6.c:(.text+0x14eee7): undefined reference to `ip6_dst_hoplimit'
l2tp_ip6.c:(.text+0x14ef8b): undefined reference to `ip6_append_data'
l2tp_ip6.c:(.text+0x14ef9d): undefined reference to `ip6_flush_pending_frames'
l2tp_ip6.c:(.text+0x14efe2): undefined reference to `ip6_push_pending_frames'
net/built-in.o: In function `l2tp_ip6_destroy_sock':
l2tp_ip6.c:(.text+0x14f090): undefined reference to `ip6_flush_pending_frames'
l2tp_ip6.c:(.text+0x14f0a0): undefined reference to `inet6_destroy_sock'
net/built-in.o: In function `l2tp_ip6_connect':
l2tp_ip6.c:(.text+0x14f14d): undefined reference to `ip6_datagram_connect'
net/built-in.o: In function `l2tp_ip6_bind':
l2tp_ip6.c:(.text+0x14f4fe): undefined reference to `ipv6_chk_addr'
net/built-in.o: In function `l2tp_ip6_init':
l2tp_ip6.c:(.init.text+0x73fa): undefined reference to `inet6_add_protocol'
l2tp_ip6.c:(.init.text+0x740c): undefined reference to `inet6_register_protosw'
net/built-in.o: In function `l2tp_ip6_exit':
l2tp_ip6.c:(.exit.text+0x1954): undefined reference to `inet6_unregister_protosw'
l2tp_ip6.c:(.exit.text+0x1965): undefined reference to `inet6_del_protocol'
net/built-in.o:(.rodata+0xf2d0): undefined reference to `inet6_release'
net/built-in.o:(.rodata+0xf2d8): undefined reference to `inet6_bind'
net/built-in.o:(.rodata+0xf308): undefined reference to `inet6_ioctl'
net/built-in.o:(.data+0x1af40): undefined reference to `ipv6_setsockopt'
net/built-in.o:(.data+0x1af48): undefined reference to `ipv6_getsockopt'
net/built-in.o:(.data+0x1af50): undefined reference to `compat_ipv6_setsockopt'
net/built-in.o:(.data+0x1af58): undefined reference to `compat_ipv6_getsockopt'
make: *** [vmlinux] Error 1
This is due to l2tp uses symbols from IPV6, so when IPV6
is a module, l2tp is not allowed to be builtin.
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Combine more modules since the actual code is so small anyway that the
kmod metadata and the module in its loaded state totally outweighs the
combined actual code size.
IP_NF_TARGET_REDIRECT becomes a compat option; IP6_NF_TARGET_REDIRECT
is completely eliminated since it has not see a release yet.
Signed-off-by: Jan Engelhardt <jengelh@inai.de>
Acked-by: Patrick McHardy <kaber@trash.net>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Combine more modules since the actual code is so small anyway that the
kmod metadata and the module in its loaded state totally outweighs the
combined actual code size.
IP_NF_TARGET_NETMAP becomes a compat option; IP6_NF_TARGET_NETMAP
is completely eliminated since it has not see a release yet.
Signed-off-by: Jan Engelhardt <jengelh@inai.de>
Acked-by: Patrick McHardy <kaber@trash.net>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
hlist walk in find_appropriate_src() is not protected anymore by rcu_read_lock(),
so rcu_read_unlock() is unnecessary if in_range() matches.
This bug was added in (c7232c9 netfilter: add protocol independent NAT core).
Signed-off-by: Ulrich Weber <ulrich.weber@sophos.com>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
When unloading a protocol module nf_ct_iterate_cleanup() is used to
remove all conntracks using the protocol from the bysource hash and
clean their NAT sections. Since the conntrack isn't actually killed,
the NAT callback is invoked twice, once for each direction, which
causes an oops when trying to delete it from the bysource hash for
the second time.
The same oops can also happen when removing both an L3 and L4 protocol
since the cleanup function doesn't check whether the conntrack has
already been cleaned up.
Pid: 4052, comm: modprobe Not tainted 3.6.0-rc3-test-nat-unload-fix+ #32 Red Hat KVM
RIP: 0010:[<ffffffffa002c303>] [<ffffffffa002c303>] nf_nat_proto_clean+0x73/0xd0 [nf_nat]
RSP: 0018:ffff88007808fe18 EFLAGS: 00010246
RAX: 0000000000000000 RBX: ffff8800728550c0 RCX: ffff8800756288b0
RDX: dead000000200200 RSI: ffff88007808fe88 RDI: ffffffffa002f208
RBP: ffff88007808fe28 R08: ffff88007808e000 R09: 0000000000000000
R10: dead000000200200 R11: dead000000100100 R12: ffffffff81c6dc00
R13: ffff8800787582b8 R14: ffff880078758278 R15: ffff88007808fe88
FS: 00007f515985d700(0000) GS:ffff88007cd00000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
CR2: 00007f515986a000 CR3: 000000007867a000 CR4: 00000000000006e0
DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
Process modprobe (pid: 4052, threadinfo ffff88007808e000, task ffff8800756288b0)
Stack:
ffff88007808fe68 ffffffffa002c290 ffff88007808fe78 ffffffff815614e3
ffffffff00000000 00000aeb00000246 ffff88007808fe68 ffffffff81c6dc00
ffff88007808fe88 ffffffffa00358a0 0000000000000000 000000000040f5b0
Call Trace:
[<ffffffffa002c290>] ? nf_nat_net_exit+0x50/0x50 [nf_nat]
[<ffffffff815614e3>] nf_ct_iterate_cleanup+0xc3/0x170
[<ffffffffa002c55a>] nf_nat_l3proto_unregister+0x8a/0x100 [nf_nat]
[<ffffffff812a0303>] ? compat_prepare_timeout+0x13/0xb0
[<ffffffffa0035848>] nf_nat_l3proto_ipv4_exit+0x10/0x23 [nf_nat_ipv4]
...
To fix this,
- check whether the conntrack has already been cleaned up in
nf_nat_proto_clean
- change nf_ct_iterate_cleanup() to only invoke the callback function
once for each conntrack (IP_CT_DIR_ORIGINAL).
The second change doesn't affect other callers since when conntracks are
actually killed, both directions are removed from the hash immediately
and the callback is already only invoked once. If it is not killed, the
second callback invocation will always return the same decision not to
kill it.
Reported-by: Jesper Dangaard Brouer <brouer@redhat.com>
Signed-off-by: Patrick McHardy <kaber@trash.net>
Acked-by: Jesper Dangaard Brouer <brouer@redhat.com>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
* NF_NAT_IPV6 requires IP6_NF_IPTABLES
* IP6_NF_TARGET_MASQUERADE, IP6_NF_TARGET_NETMAP, IP6_NF_TARGET_REDIRECT
and IP6_NF_TARGET_NPT require NF_NAT_IPV6.
This change just mirrors what IPv4 does in Kconfig, for consistency.
Reported-by: Randy Dunlap <rdunlap@xenotime.net>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Jeff Kirsher says:
====================
This series contains updates to igb and ixgbevf.
v2: updated patch description in 04 patch (ixgbevf: scheduling while
atomic in reset hw path)
...
Akeem G. Abodunrin (1):
igb: Support to enable EEE on all eee_supported devices
Alexander Duyck (2):
igb: Remove artificial restriction on RQDPC stat reading
ixgbevf: Add support for VF API negotiation
John Fastabend (1):
ixgbevf: scheduling while atomic in reset hw path
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
Remove unnecessary temporary variable and #ifdef DEBUG block.
Signed-off-by: Joe Perches <joe@perches.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
The dbg() USB macro is so old, it predates me. The USB networking drivers are
the last hold-out using this macro, and we want to get rid of it, so replace
the usage of it with the proper netdev_dbg() or dev_dbg() (depending on the
context) calls.
Some places we end up using a local variable for the debug call, so also
convert the other existing dev_* calls to use it as well, to save tiny amounts
of code space.
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Both tcp_timewait_state_process and tcp_check_req use the same basic
construct of
struct tcp_options received tmp_opt;
tmp_opt.saw_tstamp = 0;
then call
tcp_parse_options
However if they are fed a frame containing a TCP_SACK then tbe code
behaviour is undefined because opt_rx->sack_ok is undefined data.
This ought to be documented if it is intentional.
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Christoph Paasch <christoph.paasch@uclouvain.be>
Acked-by: H.K. Jerry Chu <hkchu@google.com>
Acked-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Add rtnl_link_ops to IPoIB, with the first usage being child device
create/delete through them. Childs devices are now either legacy ones,
created/deleted through the ipoib sysfs entries, or RTNL ones.
Adding support for RTNL childs involved refactoring of ipoib_vlan_add
which is now used by both the sysfs and the link_ops code.
Also, added ndo_uninit entry to support calling unregister_netdevice_queue
from the rtnl dellink entry. This required removal of calls to
ipoib_dev_cleanup from the driver in flows which use unregister_netdevice,
since the networking core will invoke ipoib_uninit which does exactly that.
Signed-off-by: Erez Shitrit <erezsh@mellanox.co.il>
Signed-off-by: Or Gerlitz <ogerlitz@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Ben Hutchings says:
====================
1. Extension to PPS/PTP to allow for PHC devices where pulses are
subject to a variable but measurable delay.
2. PPS/PTP/PHC support for Solarflare boards with a timestamping
peripheral.
3. MTD support for updating the timestamping peripheral on those boards.
4. Fix for potential over-length requests to firmware.
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
This change makes it so that the VF can support the PF/VF API negotiation
protocol. Specifically in this case we are adding support for API 1.0
which will mean that the VF is capable of cleaning up buffers that span
multiple descriptors without triggering an error.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Sibai Li <sibai.li@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Current implementation enables EEE on only i350 device. This patch enables
EEE on all eee_supported devices. Also, configured LPI clock to keep
running before EEE is enabled on i210 and i211 devices.
Signed-off-by: Akeem G. Abodunrin <akeem.g.abodunrin@intel.com>
Tested-by: Jeff Pieper <jeffrey.e.pieper@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
For some reason the reading of the RQDPC register was being artificially
limited to 4K. Instead of limiting the value we should read the value and
add the full amount. Otherwise this can lead to a misleading number of
dropped packets when the actual value is in fact much higher.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Jeff Pieper <jeffrey.e.pieper@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
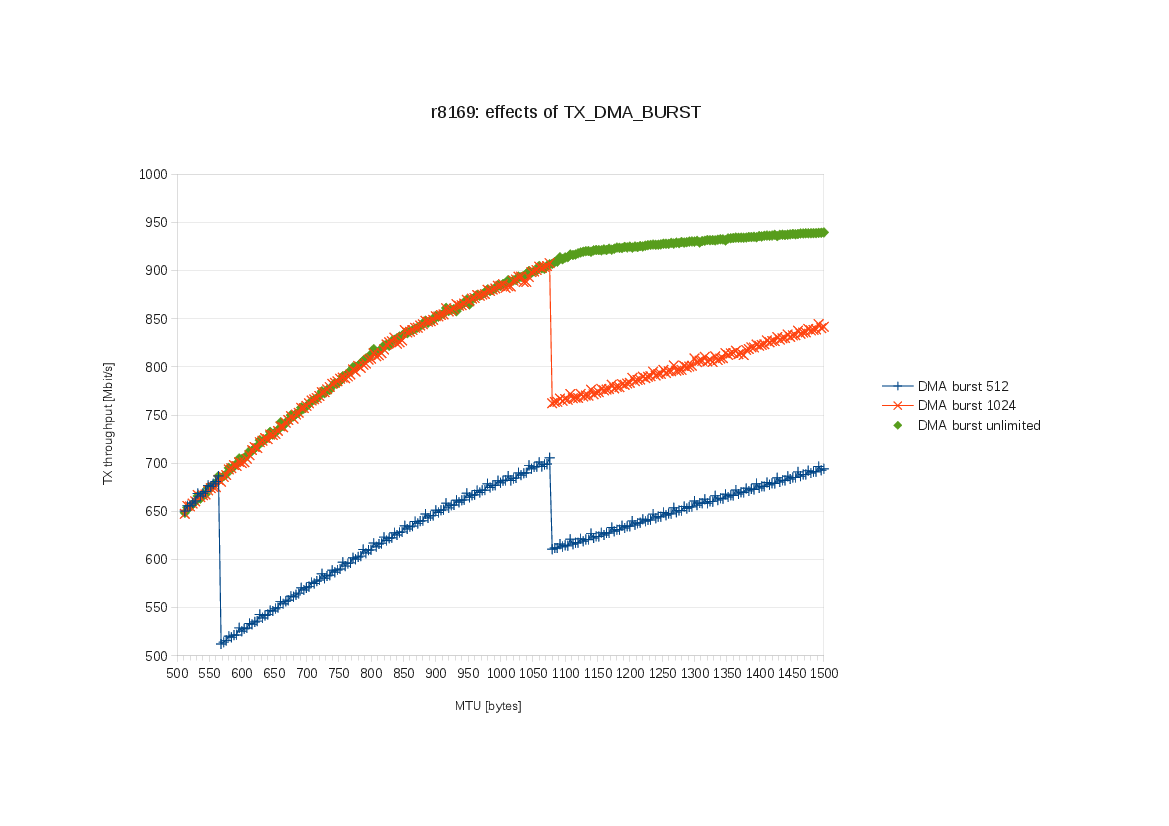
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Two years ago, Shan Wei tried to fix this:
http://patchwork.ozlabs.org/patch/43905/
The problem is that RFC2460 requires an ICMP Time
Exceeded -- Fragment Reassembly Time Exceeded message should be
sent to the source of that fragment, if the defragmentation
times out.
"
If insufficient fragments are received to complete reassembly of a
packet within 60 seconds of the reception of the first-arriving
fragment of that packet, reassembly of that packet must be
abandoned and all the fragments that have been received for that
packet must be discarded. If the first fragment (i.e., the one
with a Fragment Offset of zero) has been received, an ICMP Time
Exceeded -- Fragment Reassembly Time Exceeded message should be
sent to the source of that fragment.
"
As Herbert suggested, we could actually use the standard IPv6
reassembly code which follows RFC2460.
With this patch applied, I can see ICMP Time Exceeded sent
from the receiver when the sender sent out 3/4 fragmented
IPv6 UDP packet.
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Cc: Hideaki YOSHIFUJI <yoshfuji@linux-ipv6.org>
Cc: Patrick McHardy <kaber@trash.net>
Cc: Pablo Neira Ayuso <pablo@netfilter.org>
Cc: netfilter-devel@vger.kernel.org
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
As pointed by Michal, it is necessary to add a new
namespace for nf_conntrack_reasm code, this prepares
for the second patch.
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Cc: Patrick McHardy <kaber@trash.net>
Cc: Pablo Neira Ayuso <pablo@netfilter.org>
Cc: netfilter-devel@vger.kernel.org
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
In netpoll tx path, we miss the chance of calling ->ndo_select_queue(),
thus could cause problems when bonding is involved.
This patch makes dev_pick_tx() extern (and rename it to netdev_pick_tx())
to let netpoll call it in netpoll_send_skb_on_dev().
Reported-by: Sylvain Munaut <s.munaut@whatever-company.com>
Cc: "David S. Miller" <davem@davemloft.net>
Cc: Eric Dumazet <edumazet@google.com>
Signed-off-by: Cong Wang <amwang@redhat.com>
Tested-by: Sylvain Munaut <s.munaut@whatever-company.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
The internal functions for add/deleting addresses don't change
their argument.
Signed-off-by: Stephen Hemminger <shemminger@vyatta.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
When building 64-bit kernel with this driver we get following warnings from
the compiler:
drivers/net/ethernet/i825xx/znet.c: In function ‘hardware_init’:
drivers/net/ethernet/i825xx/znet.c:863:29: warning: cast from pointer to integer of different size [-Wpointer-to-int-cast]
drivers/net/ethernet/i825xx/znet.c:870:29: warning: cast from pointer to integer of different size [-Wpointer-to-int-cast]
Fix these by calling isa_virt_to_bus() before passing the pointers to
set_dma_addr().
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Add GSO support to GRE tunnels.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Maciej Żenczykowski <maze@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Instead of forcing device drivers to provide empty ethtool_ops or tweak
net/core/ethtool.c again, we could provide a generic ethtool_ops.
This occurred to me when I wanted to add GSO support to GRE tunnels.
ethtool -k support should be generic for all drivers.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Ben Hutchings <bhutchings@solarflare.com>
Cc: Maciej Żenczykowski <maze@google.com>
Reviewed-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
When moving a nic from net namespace A to net namespace B,
in dev_change_net_namesapce,we call __dev_get_by_name to
decide if the netns B has the device has the same name.
if the netns B already has the same named device,we call
dev_get_valid_name to try to get a valid name for this nic in
the netns B,but net_device->nd_net still point to netns A now.
this patch fix it.
Signed-off-by: Gao feng <gaofeng@cn.fujitsu.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
If dst cache dst_a copies from dst_b, and dst_b copies from dst_c, check
if dst_a is expired or not, we should not end with dst_a->dst.from, dst_b,
we should check dst_c.
CC: Gao feng <gaofeng@cn.fujitsu.com>
Signed-off-by: Li RongQing <roy.qing.li@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
{kind=link}